论文阅读
Multi-AMP: 多重对抗动作先验学习高级技能
AMP 的进阶版:用多个判别器分别建模不同风格(站立/行走/坐下等),让机器人按指令精确切换风格,并安全完成'坐下'这种传统 RL 难调参的高风险动作。
问题
-
AMP 的单一性限制: 原版 AMP 通常一次只学一种风格。如果你把“走路”和“站立”的数据混在一起给它,它可能会学出一个不伦不类的混合动作,或者无法根据指令精确切换风格 。
-
“坐下”动作极难调参: 让机器人从站立状态“坐下”非常危险。如果用传统 RL(人工设计奖励),机器人往往会直接“砸”在地上,导致膝盖电机过载损坏 。
-
技能遗忘: 按照顺序一个接一个地学技能,机器人容易学了新的忘了旧的(灾难性遗忘)。
核心技术
多重判别器架构 (Multi-AMP Architecture)
Multi-AMP 的核心逻辑是:给 AMP 加上一个“多路开关”。
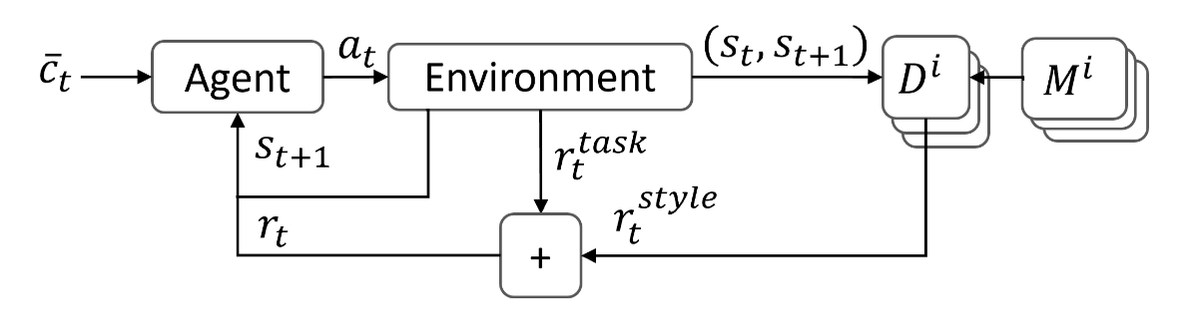
-
输入端 (Agent): 机器人的大脑(Policy)。它接收的输入不仅仅是状态 ,还多了一个指令 。
-
关键创新: 这个 里包含了一个 One-hot 向量 (Style Selector)。
-
例子: 如果有3个风格(走、蹲、站), 就是
[1, 0, 0]或[0, 1, 0]。这告诉 Policy:“现在你要模仿第几个老师”。
-
-
中间处理 (Discriminators): 系统里不再是一个判别器,而是 个判别器 () 。
- 每个判别器负责一种风格(比如 只看过“走路”的数据, 只看过“蹲下”的数据)。
- 只有被 选中的那个判别器会被激活,其他的暂时休眠。
-
输出端 (Reward):
- 被激活的判别器打分,生成 风格奖励 。
- 环境根据任务完成度(如速度),生成 任务奖励 。
- 两者相加 ,指导机器人更新策略。


“倒放录像”学习法 (Reverse Playback for Sitting Down)
为什么“坐下”对于机器人很难?
这是一个非常敏锐的问题。按照 AMP 的逻辑,确实应该是“给个视频就能学会”。但在轮足机器人(Wheeled-legged robot)这个特定场景下,情况变得复杂了。
A. 为什么难?(物理与硬件的限制)
-
膝盖受不了 (Hardware Safety): 论文中明确提到,如果只用任务奖励(告诉机器人“把屁股放低”),机器人学会的策略往往是“直接向前摔倒”。
-
这种动作会导致膝盖关节承受巨大的冲击力(High impulses)。
-
这种冲击力会超过机器人的安全扭矩阈值 (Safety torque threshold),导致硬件损坏 。
-
-
受控的“失稳”: “坐下”本质上是一个重心后移并下降的过程。对于高重心的轮足机器人,这很容易变成不可控的向后翻倒。要做到“温柔地”坐下,需要极高的控制精度。
B. 为什么“只要有一个坐下的视频”还不够?
理论上如果有完美的坐下视频是可以的,但现实中有两个障碍:
- 数据获取困难 (Chicken-and-Egg Problem):
- 去哪里找这个“完美的坐下视频”?
- 如果让操作员遥控机器人录制,操作员也很难控制得那么完美、温柔。
- 如果用这一台机器人去模仿其他不同结构的机器人(如真狗)的坐下,可能会因为身体结构差异(轮子 vs 脚)导致物理不可行。
- 安全性与可行性:
- 即使有视频,如果视频里的动作稍微快了一点,机器人模仿时产生的动量(Momentum)可能就会导致撞击地面。
C. 作者的“神操作”:倒放录像 (Reverse Playback)
作者没有去录“坐下”的视频,而是录了“站起来”的视频,然后倒放给 AMP 看 。
-
为什么“倒放”是完美的解决方案?
-
初始速度为 0:“站起来”动作的开始时刻(趴在地上),速度是 0。
-
倒放后的终止速度为0: 当你把“站起来”倒放,它就变成了“坐下”。最妙的是,这个倒放动作的结尾(屁股着地那一刻)速度正好是 0 。
-
物理含义: 这意味着机器人学会的是一种“软着陆” (Soft Landing)。它会模仿视频,在接触地面前自动减速,把冲击力降到最低。
-
对比结果 (Figure 5):
-
无 Style Reward: 机器人前腿伸直,像僵尸一样直挺挺地向前倒,膝盖重砸地面(蓝色轨迹)。
-
倒放 Style Reward: 机器人先屈膝,降低重心,然后温柔地向后坐,冲击力极小(绿色轨迹)。
总结: “坐下”难在硬件安全。AMP 虽然强大,但需要“好教材”。作者通过“倒放站立”创造了物理上最安全、最温柔的“完美教材”,从而让 Multi-AMP 轻松学会了这个高难度动作。

Written by
ZZC
每天研究怎么摸鱼的神人
Comments
评论功能即将上线