在上一节中我们介绍过了 return,return 之所以很重要,是因为 return 可以帮助我们直观地确定哪一种策略更好。
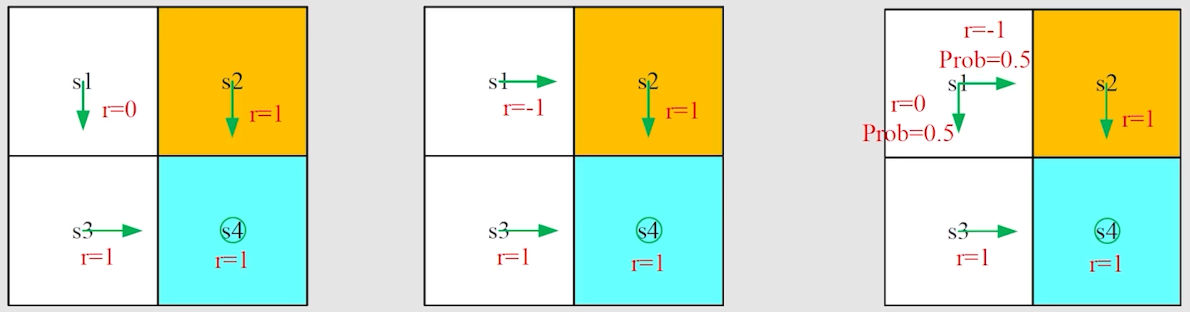
对于上面的例子,我们可以计算出各个 return 如下:
r e t u r n 1 = 0 + γ 1 + γ 2 1 + γ 3 1 + ⋯ = γ 1 − γ r e t u r n 2 = 1 + γ 1 + γ 2 1 + γ 3 1 + ⋯ = 1 + γ 1 − γ r e t u r n 3 = 0.5 × r e t u r n 1 + 0.5 × r e t u r n 2 = 0.5 + γ 1 − γ r e t u r n 2 > r e t u r n 3 > r e t u r n 1 return_1 = 0+\gamma1+\gamma^21+\gamma^31+\dots=\frac{\gamma}{1-\gamma} \\
return_2=1+\gamma1+\gamma^21+\gamma^31+\dots=1+\frac{\gamma}{1-\gamma} \\
return_3 = 0.5 \times return_1 + 0.5 \times return_2=0.5+\frac{\gamma}{1-\gamma} \\
return_2 > return_3 > return_1 r e t u r n 1 = 0 + γ 1 + γ 2 1 + γ 3 1 + ⋯ = 1 − γ γ r e t u r n 2 = 1 + γ 1 + γ 2 1 + γ 3 1 + ⋯ = 1 + 1 − γ γ r e t u r n 3 = 0.5 × r e t u r n 1 + 0.5 × r e t u r n 2 = 0.5 + 1 − γ γ r e t u r n 2 > r e t u r n 3 > r e t u r n 1 得到第一种策略优于第三种策略优于第二种策略。
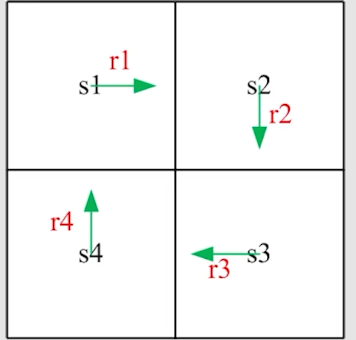
下面我们来看一种情况,计算各个 return:
让 v i v_i v i s i s_i s i
v 1 = r 1 + γ r 2 + γ 2 r 3 + … v 2 = r 2 + γ r 3 + γ 2 r 4 + … v 3 = r 3 + γ r 4 + γ 2 r 1 + … v 4 = r 4 + γ r 1 + γ 2 r 2 + … v_1 = r_1+\gamma r_2+\gamma^2 r_3+\dots \\
v_2 = r_2+\gamma r_3+\gamma^2 r_4+\dots \\
v_3=r_3+\gamma r_4 + \gamma^2 r_1 + \dots \\
v_4 = r_4 + \gamma r_1 + \gamma^2 r_2 + \dots v 1 = r 1 + γ r 2 + γ 2 r 3 + … v 2 = r 2 + γ r 3 + γ 2 r 4 + … v 3 = r 3 + γ r 4 + γ 2 r 1 + … v 4 = r 4 + γ r 1 + γ 2 r 2 + … 这种方法非常直观,但实际上,我们还有另外一种计算方法:
v 1 = r 1 + γ v 2 v 2 = r 2 + γ v 3 v 3 = r 3 + γ v 4 v 4 = r 4 + γ v 1 v_1 = r_1+\gamma v_2 \\
v_2 = r_2+\gamma v_3 \\
v_3 = r_3 +\gamma v_4 \\
v_4 = r_4 + \gamma v_1 v 1 = r 1 + γ v 2 v 2 = r 2 + γ v 3 v 3 = r 3 + γ v 4 v 4 = r 4 + γ v 1 这告诉我们,一个状态的 return 实际上是依赖于别的状态的 return 的。在强化学习中我们称之为 Bootstrapping 。
上面的公式还可以写成矩阵形式:
[ v 1 v 2 v 3 v 4 ] ⏟ v = [ r 1 r 2 r 3 r 4 ] + [ γ v 2 γ v 3 γ v 4 γ v 1 ] = [ r 1 r 2 r 3 r 4 ] ⏟ r + γ [ 0 1 0 0 0 0 1 0 0 0 0 1 1 0 0 0 ] ⏟ P [ v 1 v 2 v 3 v 4 ] ⏟ v \underbrace{\begin{bmatrix} v_1 \\ v_2 \\ v_3 \\ v_4 \end{bmatrix}}_{\mathbf{v}}
=
\begin{bmatrix} r_1 \\ r_2 \\ r_3 \\ r_4 \end{bmatrix}
+
\begin{bmatrix} \gamma v_2 \\ \gamma v_3 \\ \gamma v_4 \\ \gamma v_1 \end{bmatrix}
=
\underbrace{\begin{bmatrix} r_1 \\ r_2 \\ r_3 \\ r_4 \end{bmatrix}}_{\mathbf{r}}
+ \gamma
\underbrace{\begin{bmatrix} 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \\ 1 & 0 & 0 & 0 \end{bmatrix}}_{\mathbf{P}}
\underbrace{\begin{bmatrix} v_1 \\ v_2 \\ v_3 \\ v_4 \end{bmatrix}}_{\mathbf{v}} v v 1 v 2 v 3 v 4 = r 1 r 2 r 3 r 4 + γ v 2 γ v 3 γ v 4 γ v 1 = r r 1 r 2 r 3 r 4 + γ P 0 0 0 1 1 0 0 0 0 1 0 0 0 0 1 0 v v 1 v 2 v 3 v 4 也就是:
v = r + γ P v \mathbf{v} = \mathbf{r} + \gamma \mathbf{P} \mathbf{v} v = r + γ Pv 其中,P \mathbf{P} P
这就是针对 specific deterministic problem 的 Bellman
考虑以下单步过程:
S t → A t R t + 1 , S t + 1 S_t \xrightarrow{A_t}R_{t+1},S_{t+1} S t A t R t + 1 , S t + 1 这个单步的过程是被以下概率所约束的:
S t → A t : π ( A t = a ∣ S t = s ) S t , A t → R t + 1 : p ( R t + 1 = r ∣ S t = s , A t = a ) S t , A t → S t + 1 : p ( S t + 1 = s ′ ∣ S t = s , A t = a ) S_t \rightarrow A_t:\pi(A_t = a \mid S_t=s)\\
S_t,A_t \rightarrow R_{t+1}:p(R_{t+1}=r \mid S_t=s,A_t=a)\\
S_t,A_t \rightarrow S_{t+1}:p(S_{t+1}=s' \mid S_t=s,A_t=a) S t → A t : π ( A t = a ∣ S t = s ) S t , A t → R t + 1 : p ( R t + 1 = r ∣ S t = s , A t = a ) S t , A t → S t + 1 : p ( S t + 1 = s ′ ∣ S t = s , A t = a ) 对于以上单步过程,我们可以推广到多步过程:
S t → A t R t + 1 , S t + 1 → A t + 1 R t + 2 , S t + 2 → A t + 2 R t + 3 , … S_t \xrightarrow{A_t}R_{t+1},S_{t+1} \xrightarrow{A_{t+1}}R_{t+2},S_{t+2} \xrightarrow{A_{t+2}}R_{t+3},\dots S t A t R t + 1 , S t + 1 A t + 1 R t + 2 , S t + 2 A t + 2 R t + 3 , … 我们记这个多步 trajectory 的 discount return 为:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + … = R t + 1 + γ G t + 1 γ ∈ [ 0 , 1 ) \begin{gather*}
\begin{aligned}
G_t &= R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \dots \\
&= R_{t+1} + \gamma G_{t+1}
\end{aligned} \\
\gamma \in [0, 1)
\end{gather*} G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + … = R t + 1 + γ G t + 1 γ ∈ [ 0 , 1 ) 像 G t G_t G t R t R_t R t S t S_t S t
在前面介绍这么多以后,我们来介绍 state value。
实际上,state value 被定义为 G t G_t G t
v π ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 ∣ S t = s ] + E [ γ G t + 1 ∣ S t = s ] = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] \begin{align*}
v_{\pi}(s) &= \mathbb{E}[G_t \mid S_t = s] \\
&=\mathbb{E}[R_{t+1}+\gamma G_{t+1} \mid S_t = s] \\
&=\mathbb{E}[R_{t+1}\mid S_t = s] + \mathbb{E}[\gamma G_{t+1} \mid S_t = s] \\
&=\mathbb{E}[R_{t+1}\mid S_t = s] + \gamma \mathbb{E}[G_{t+1} \mid S_t = s]
\end{align*} v π ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 ∣ S t = s ] + E [ γ G t + 1 ∣ S t = s ] = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] 需要注意以下几点:
状态从 s 开始
基于 policy π \pi π
state value 越高,说明策略越好
Return value 和 state value 是什么关系?
The state value is the mean of all possible returns that can be obtained starting from a state.
若所有 - π ( a ∣ s ) \pi(a|s) π ( a ∣ s ) p ( r ∣ s , a ) p(r|s, a) p ( r ∣ s , a ) p ( s ′ ∣ s , a ) p(s'|s, a) p ( s ′ ∣ s , a )
推导过程如下所示:
E [ G t + 1 ∣ S t = s ] = ∑ s ′ E [ G t + 1 ∣ S t = s , S t + 1 = s ′ ] p ( s ′ ∣ s ) = ∑ s ′ E [ G t + 1 ∣ S t + 1 = s ′ ] p ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) p ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) ∑ a p ( s ′ ∣ s , a ) π ( a ∣ s ) \begin{align*}
\mathbb{E}[G_{t+1} | S_t = s] &= \sum_{s'} \mathbb{E}[G_{t+1} | S_t = s, S_{t+1} = s'] p(s'|s) \\
&= \sum_{s'} \mathbb{E}[G_{t+1} | S_{t+1} = s'] p(s'|s) \\
&= \sum_{s'} v_{\pi}(s') p(s'|s) \\
&= \sum_{s'} v_{\pi}(s') \sum_{a} p(s'|s, a) \pi(a|s)
\end{align*} E [ G t + 1 ∣ S t = s ] = s ′ ∑ E [ G t + 1 ∣ S t = s , S t + 1 = s ′ ] p ( s ′ ∣ s ) = s ′ ∑ E [ G t + 1 ∣ S t + 1 = s ′ ] p ( s ′ ∣ s ) = s ′ ∑ v π ( s ′ ) p ( s ′ ∣ s ) = s ′ ∑ v π ( s ′ ) a ∑ p ( s ′ ∣ s , a ) π ( a ∣ s ) 结合上面的公式,可以推导出:
v π ( s ) = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] , = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r ⏟ mean of immediate rewards + γ ∑ a π ( a ∣ s ) ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ⏟ mean of future rewards , = ∑ a π ( a ∣ s ) [ ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ] , ∀ s ∈ S . \begin{align*}
\textcolor{red}{v_{\pi}(s)} &= \mathbb{E}[R_{t+1} \mid S_t = s] + \gamma \mathbb{E}[G_{t+1} \mid S_t = s], \\
&= \textcolor{blue}{\underbrace{\color{black}\sum_{a} \pi(a|s) \sum_{r} p(r|s, a)r}_{\text{mean of immediate rewards}}} + \textcolor{blue}{\underbrace{\color{black}\gamma \sum_{a} \pi(a|s) \sum_{s'} p(s'|s, a) \textcolor{red}{v_{\pi}(s')}}_{\text{mean of future rewards}}}, \\
&= \textcolor{blue}{\sum_{a} \pi(a|s) \left[ \sum_{r} p(r|s, a)r + \gamma \sum_{s'} p(s'|s, a) \textcolor{red}{v_{\pi}(s')} \right]}, \quad \forall s \in \mathcal{S}.
\end{align*} v π ( s ) = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] , = mean of immediate rewards a ∑ π ( a ∣ s ) r ∑ p ( r ∣ s , a ) r + mean of future rewards γ a ∑ π ( a ∣ s ) s ′ ∑ p ( s ′ ∣ s , a ) v π ( s ′ ) , = a ∑ π ( a ∣ s ) [ r ∑ p ( r ∣ s , a ) r + γ s ′ ∑ p ( s ′ ∣ s , a ) v π ( s ′ ) ] , ∀ s ∈ S . 看似这里只有一条式子,且 v π ( s ) v_{\pi}(s) v π ( s ) v π ( s ) v_{\pi}(s) v π ( s ) ∀ s ∈ S \forall s \in S ∀ s ∈ S
π ( a ∣ s ) \pi(a \mid s) π ( a ∣ s ) policy evaluation 。p ( r ∣ s , a ) p(r \mid s,a) p ( r ∣ s , a ) p ( s ′ ∣ s , a ) p(s' \mid s,a) p ( s ′ ∣ s , a )
v π ( s ) = ∑ a π ( a ∣ s ) [ ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ] , ∀ s ∈ S . v_{\pi}(s)= {\sum_{a} \pi(a|s) \left[ \sum_{r} p(r|s, a)r + \gamma \sum_{s'} p(s'|s, a){v_{\pi}(s')} \right]}, \quad \forall s \in \mathcal{S}. v π ( s ) = a ∑ π ( a ∣ s ) [ r ∑ p ( r ∣ s , a ) r + γ s ′ ∑ p ( s ′ ∣ s , a ) v π ( s ′ ) ] , ∀ s ∈ S . 对于上面的贝尔曼表达式,我们可以进行一些处理:
r π ( s ) ≐ ∑ a ∈ A π ( a ∣ s ) ∑ r ∈ R p ( r ∣ s , a ) r p π ( s ′ ∣ s ) ≐ ∑ a ∈ A π ( a ∣ s ) p ( s ′ ∣ s , a ) v π ( s ) = r π ( s ) + γ ∑ s ′ p π ( s ′ ∣ s ) v π ( s ′ ) r_{\pi}(s) \doteq \sum_{a \in \mathcal{A}} \pi(a|s) \sum_{r \in \mathcal{R}} p(r|s, a)r \\
p_{\pi}(s'|s) \doteq \sum_{a \in \mathcal{A}} \pi(a|s) p(s'|s, a) \\
v_{\pi}(s)=r_{\pi}(s)+\gamma \sum_{s'}p_{\pi}(s' \mid s)v_{\pi}(s') r π ( s ) ≐ a ∈ A ∑ π ( a ∣ s ) r ∈ R ∑ p ( r ∣ s , a ) r p π ( s ′ ∣ s ) ≐ a ∈ A ∑ π ( a ∣ s ) p ( s ′ ∣ s , a ) v π ( s ) = r π ( s ) + γ s ′ ∑ p π ( s ′ ∣ s ) v π ( s ′ ) 其中,r π ( s ) r_{\pi}(s) r π ( s ) s s s p π ( s ′ ∣ s ) p_{\pi}(s' \mid s) p π ( s ′ ∣ s ) s s s s ′ s' s ′
详细解释r π ( s ) r_{\pi}(s) r π ( s ) ∑ r ∈ R p ( r ∣ s , a ) r \sum_{r \in \mathcal{R}} p(r|s, a)r ∑ r ∈ R p ( r ∣ s , a ) r s s s a a a
我们对每一个状态 states 标号为 s i ( i = 1 , … , n ) s_i \; (i=1,\dots,n) s i ( i = 1 , … , n )
v π ( s i ) = r π ( s i ) + γ ∑ s j p π ( s j ∣ s i ) v π ( s j ) v_{\pi}(s_i)=r_{\pi}(s_i)+\gamma \sum_{s_j}p_{\pi}(s_j \mid s_i)v_{\pi}(s_j) v π ( s i ) = r π ( s i ) + γ s j ∑ p π ( s j ∣ s i ) v π ( s j ) 将所有的这些公式放在一起,并写成向量形式:
v π = r π + γ P π v π v π = [ v π ( s 1 ) , … , v π ( s n ) ] T ∈ R n r π = [ r π ( s 1 ) , … , r π ( s n ) ] T ∈ R n P π ∈ R n × n , [ P π ] i j = p π ( s j ∣ s i ) , v_{\pi}=r_{\pi}+\gamma P_{\pi}v_{\pi} \\
v_{\pi} = [v_{\pi}(s_1), \ldots, v_{\pi}(s_n)]^T \in \mathbb{R}^n \\
r_{\pi} = [r_{\pi}(s_1), \ldots, r_{\pi}(s_n)]^T \in \mathbb{R}^n \\
P_{\pi} \in \mathbb{R}^{n \times n},[P_{\pi}]_{ij} = p_{\pi}(s_j|s_i), v π = r π + γ P π v π v π = [ v π ( s 1 ) , … , v π ( s n ) ] T ∈ R n r π = [ r π ( s 1 ) , … , r π ( s n ) ] T ∈ R n P π ∈ R n × n , [ P π ] ij = p π ( s j ∣ s i ) , 其中,P π P_{\pi} P π
给定一个 policy,找到一个对应的 state value 的过程被称为 policy evaluation 。
我们可以根据公式直接计算得到(closed-form solution):
v π = ( I − γ P π ) − 1 r π v_{\pi}=(I-\gamma P_{\pi})^{-1}r_{\pi} v π = ( I − γ P π ) − 1 r π 但实际上,我们并不会使用这个公式,因为这个公式需要求一个矩阵的逆,这很费时。
实际上,可以使用迭代法 来进行计算:
v k + 1 = r π + γ P π v k v_{k+1}=r_{\pi}+\gamma P_{\pi}v_{k} v k + 1 = r π + γ P π v k 刚开始时,我们随便代入一个变量 v 0 v_0 v 0
v k → v π = ( I − γ P π ) − 1 r π , k → ∞ v_k \rightarrow v_{\pi}=(I-\gamma P_{\pi})^{-1}r_{\pi}, \; k \rightarrow \infin v k → v π = ( I − γ P π ) − 1 r π , k → ∞ 上面相关的证明如下:
Action value 指的是 the average return the agent can get starting from a state and taking an action ,也就是:
q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] q_{\pi}(s,a)=\mathbb{E}_{\pi}[G_{t} \mid S_t=s,A_t=a] q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] 其与 state value 有如下关系:
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ⋅ q π ( s , a ) v_{\pi}(s)=\sum_{a \in \mathcal{A}}\pi(a \mid s) \cdot q_{\pi}(s,a) v π ( s ) = a ∈ A ∑ π ( a ∣ s ) ⋅ q π ( s , a ) 结合之前贝尔曼公式的形式,我们可以得到:
q π ( s , a ) = ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) q_{\pi}(s,a)=\sum_{r} p(r \mid s, a)r + \gamma \sum_{s'} p(s'\mid s, a){v_{\pi}(s')} q π ( s , a ) = r ∑ p ( r ∣ s , a ) r + γ s ′ ∑ p ( s ′ ∣ s , a ) v π ( s ′ ) 根据上面的两个公式,我们可以知道:
若我们知道所有的 v π ( s ) v_{\pi}(s) v π ( s ) q π ( s , a ) q_{\pi}(s,a) q π ( s , a )
若我们知道所有的 Action value q π ( s , a ) q_{\pi}(s,a) q π ( s , a ) v π ( s ) v_{\pi}(s) v π ( s )