我们以一个例子作为引入:
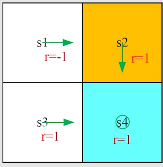
于是显然有:
v_{\pi}(s_1) &= -1 + \gamma v_{\pi}(s_2), \\
v_{\pi}(s_2) &= +1 + \gamma v_{\pi}(s_4), \\
v_{\pi}(s_3) &= +1 + \gamma v_{\pi}(s_4), \\
v_{\pi}(s_4) &= +1 + \gamma v_{\pi}(s_4).
假设 γ=0.9,计算得到:
vπ(s4)=vπ(s3)=vπ(s2)=10,vπ(s1)=8
于是我们就可以计算得到每一个状态的所有的 Action value:
qπ(s1,a1)qπ(s1,a2)qπ(s1,a3)qπ(s1,a4)qπ(s1,a5)=−1+γvπ(s1)=6.2,=−1+γvπ(s2)=8,=0+γvπ(s3)=9,=−1+γvπ(s1)=6.2,=0+γvπ(s1)=7.2.
对于原来的策略,我们可以写成:
π(a∣s1)={10a=a2a=a2
我们可以发现,原来的策略并不是最好的,因为它走进了 forbidden area。于是,我们可以把策略换成 action value 最大的那一条路:
πnew(a∣s1)={10a=a∗a=a∗a∗=argamaxqπ(s1,a)=a3.
直观上来来理解,选择一个 action value 最大 action 就可以获得一个最好的策略。
但在数学上,有时候仅仅一次的选择不能保证整个 π 的选择都是最优的。(我们需要从终点向起点开始,一步步保证最优)于是可以选择多迭代几轮来达到整体的最优。
我们定义策略 π1 比 π2 更优(better)如果:
vπ1(s)≥vπ2(s)foralls∈S
同时定义策略 π∗ 是最优(optimal)的若:
vπ∗(s)≥vπ(s)forallsandotherpolicyπ
v(s)=πmaxa∑π(a∣s)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)v(s′)),∀s∈S=πmaxa∑π(a∣s)q(s,a)s∈S
以上就是 BOE。我们的目标是求出一个最优的策略 π,使得 v(s) 的值最大。
类似的我们可以将贝尔曼最优公式写成向量形式:
v=πmax(rπ+γPπv)[rπ]s≜a∑π(a∣s)r∑p(r∣s,a)r[Pπ]s,s′=p(s′∣s)≜a∑π(a∣s)s′∑p(s′∣s,a)
这里第二三行的下标指的是向量中的一项。比如 [Pπ]s,s′,指的是 [Pπ] 中的第 s 行,第 s′ 列。
我们先来处理贝尔曼最优公式的右边的最大(max)部分。
回顾最优策略的定义,我们知道其要对任意状态 s 都要成立,因此我们先考虑一个特殊的状态 s:
v(s)=πmaxa∑π(a∣s)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)v(s′)),∀s∈S=πmaxa∑π(a∣s)q(s,a)s∈S
我们知道,∑aπ(a∣s)=1,且对于一个场景来说,q(s,a)是确定的。因此有:
πmaxa∑π(a∣s)q(s,a)≤a∑π(a∣s)⋅a∈Amaxq(s,a)=a∈Amaxq(s,a)
当且仅当:
π(a∣s)={ 1 0a=a∗a=a∗a∗=argamaxq(s,a)
对于这里的推导,一种可能的解释是,q(s,a) 确实依赖于我们之前所算出来的策略 π,但是,在优化的过程中,我们始终将此次的 q(s,a) 看作是一个定值进行计算。经过多次迭代后,一定会得到最优解。
经过上面的分析,我们知道 π 和 v 之间有密不可分的联系。不妨将 π 视作 v 的一个函数,我们就能得到:
f(v):=πmax(rπ+γPπv)
于是就有:
v=f(v)where[f(v)]s=πmaxa∑π(a∣s)q(s,a),s∈S
显然,这是一个有关不动点的问题。
在继续正文部分之前,我们首先来介绍一下不动点(Fixed point)以及 Contraction mapping theorem。
我们称一个点 x∈X 为函数 f:X→X 的 Fixed point 若:
f(x)=x
我们称 f 为一个 contraction mapping 若:
∣∣f(x1)−f(x2)∣∣≤γ∣∣x1−x2∣∣γ∈(0,1)
此处的两个 ∣∣ 操作,一个用于取绝对值,一个用于计算矩阵的值。
对任何形如 x=f(x) 的等式来说,若 f 为 contraction mapping,则:
- 必定存在一个不动点 x∗,满足 f(x∗)=x∗
- 这个不动点 x∗ 是唯一的
- 考虑一组序列 {xk},满足 xk+1=f(xk)。当 k→∞ 的时候,xk→x∗。而且,增长率是指数级别增加的(非常快)
回到正文,对于贝尔曼最优方程 v=f(v)=maxπ(rπ+γPπv) 来说,有:
∣∣f(v1)−f(v2)∣∣≤γ∣∣v1−v2∣∣
所以,f(v)=v 是 contraction mapping 的。因此由 BOE 的三条性质,我们知道:
- 对于 BOE v=f(v)=maxπ(rπ+γPπv) 来说,一定存在一个唯一的答案,而且这个答案可以被递归的计算出来:
vk+1=f(vk)=πmax(rπ+γPπvk)
这个式子的收敛程度是指数级快的,且收敛等级是由 γ 所决定的。
假设 v∗ 是贝尔曼最优方程的解,那么就会满足下面的式子:
v∗=πmax(rπ+γPπv∗)
假设:
π∗=argπmax(rπ+γPπv∗)
于是就有:
v∗=rπ∗+γPπ∗v∗
其中,π∗ 是最优策略且 v∗=vπ∗ 是对应的 state value。
至于为什么 v∗ 和 π∗ 是最优的,我们可以参考以下证明过程:

由上面的推导中,我们可以总结出一个 theorem(Greedy Optimal Policy):
对任意 s∈S,the deterministic greedy policy:
π∗(a∣s)={10a=a∗(s)a=a∗(s)
是一个可以解决 BOE 的 optimal policy。此时:
a∗(s)=argamaxq∗(a,s)
且:
π∗(s)=argπmaxa∑π(a∣s)q∗(s,a)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)v∗(s′))
我们接下来分析影响最优策略的因素:
v(s)=πmaxa∑π(a∣s)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)v(s′))
观察公式,我们可以发现正是红色部分的内容影响了最优策略:
- Reward design:r
- System model:p(s′∣s,a),p(r∣s,a)
- Discount rate:γ
对于 discount rate γ 来说,越高代表越远视,越低代表越近视。
接下了我们来看一种特殊的情况,我们改变奖励 r→αr+β。
可以证明的是,改变后的最优策略以及 state value 相对大小关系并未改变。
v′=αv∗+1−γβ1
具体证明如下所示:


