Model 通常指“环境的运行规律”,也就是我们前面经常提到的状态转移概率 P ( s ′ ∣ s , a ) P(s' \mid s,a) P ( s ′ ∣ s , a ) R ( s , a ) R(s,a) R ( s , a )
强化学习有两种,Model-based 和 Model-free。前者先构建出 P P P R R R
举个例子,假如我们投掷硬币,结果记为随机变量 X X X X = + 1 X=+1 X = + 1 X = − 1 X=-1 X = − 1 E [ X ] \mathbb{E}[X] E [ X ]
使用 Model-based 的方法,我们首先需要知道各个动作发生的概率。我们假设:
p ( X = 1 ) = 0.5 , p ( X = − 1 ) = 0.5 , ∴ E [ X ] = ∑ x x p ( x ) = 0 p\left(X=1\right)=0.5,\;p\left(X=-1\right)=0.5,\\
\therefore \mathbb{E}[X]=\sum_xxp(x)=0 p ( X = 1 ) = 0.5 , p ( X = − 1 ) = 0.5 , ∴ E [ X ] = x ∑ x p ( x ) = 0 但是在实际中,我们不可能知道准确的概率 p p p
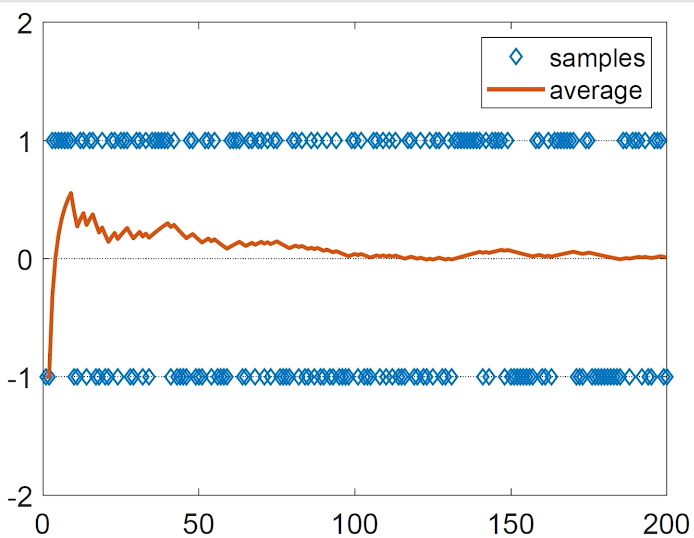
Model-free 方法的思想是,当抛硬币的次数足够多后,就可以计算结果的平均。也就是:
E [ X ] ≈ x ˉ = 1 N ∑ j = 1 N x j \mathbb{E}[X] \approx \bar{x}
= \frac{1}{N} \sum_{j=1}^{N} x_j E [ X ] ≈ x ˉ = N 1 j = 1 ∑ N x j 在这里,{ x 1 , x 2 , … , x N } \{x_1,x_2,\dots,x_N\} { x 1 , x 2 , … , x N }
结果如上所示。可以看到,当 N N N N N N
上面的结果可以用大数定理来证明:
Law of Large Numbers
对于随机变量 X X X { x j } j = 1 N \{x_j\}_{j=1}^N { x j } j = 1 N 独立同分布 的样本。让 x ˉ = 1 N ∑ j = 1 N x j \bar x = \frac{1}{N}\sum_{j=1}^Nx_j x ˉ = N 1 ∑ j = 1 N x j
E [ x ˉ ] = E [ X ] Var [ x ˉ ] = 1 N Var [ X ] \mathbb{E}[\bar x]=\mathbb{E}[X] \\
\operatorname{Var}[\bar x]=\frac{1}{N} \operatorname{Var}[X] E [ x ˉ ] = E [ X ] Var [ x ˉ ] = N 1 Var [ X ] 当 N → ∞ N \rightarrow \infin N → ∞ 1 N Var [ X ] → 0 \frac{1}{N} \operatorname{Var}[X] \rightarrow 0 N 1 Var [ X ] → 0 x ˉ \bar x x ˉ
实际上,这个算法最本质的想法就是将 Policy iteration 中的一部分转换成 model-free。
在之前的课程中我们知道,policy iteration 中有一下两部分:
Policy evaluation:v π k = r π k + γ P π k v π k v_{\pi_k}=r_{\pi_k}+\gamma P_{\pi_k}v_{\pi_k} v π k = r π k + γ P π k v π k
Policy improvement:π k + 1 = arg max π ( r π + γ P π v π k ) \pi_{k+1}=\arg \max_\pi(r_\pi+\gamma P_\pi v_{\pi_k}) π k + 1 = arg max π ( r π + γ P π v π k )
针对 policy improvement,在之前的课程中,我们都是使用其 elementwise form,也就是:
π k + 1 ( s ) = arg max π ∑ a π ( a ∣ s ) [ ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π k ( s ′ ) ] = arg max π ∑ a π ( a ∣ s ) q π k ( s , a ) , s ∈ S . \begin{align}
\pi_{k+1}(s)
&= \arg\max_{\pi} \sum_{a} \pi(a \mid s)
\left[
\sum_{r} p(r \mid s,a)\, r
+ \gamma \sum_{s'} p(s' \mid s,a)\, v_{\pi_k}(s')
\right] \\
&= \arg\max_{\pi} \sum_{a} \pi(a \mid s)\, q_{\pi_k}(s,a),
\qquad s \in \mathcal{S}.
\end{align} π k + 1 ( s ) = arg π max a ∑ π ( a ∣ s ) [ r ∑ p ( r ∣ s , a ) r + γ s ′ ∑ p ( s ′ ∣ s , a ) v π k ( s ′ ) ] = arg π max a ∑ π ( a ∣ s ) q π k ( s , a ) , s ∈ S . 在上面的公式中,关键是 q π k ( s , a ) q_{\pi_k}(s,a) q π k ( s , a )
我们有两种方法计算 q π k ( s , a ) q_{\pi_k}(s,a) q π k ( s , a )
q π k ( s , a ) = ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π k ( s ′ ) q_{\pi_k}(s,a)=\sum_{r}p(r \mid s,a)r+\gamma \sum_{s'}p(s' \mid s,a)v_{\pi_k}(s') q π k ( s , a ) = ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π k ( s ′ ) q π k ( s , a ) = E [ G t ∣ S t = s , A t = a ] q_{\pi_k}(s,a)=\mathbb{E}[G_t \mid S_t=s,A_t=a] q π k ( s , a ) = E [ G t ∣ S t = s , A t = a ]
下面展示如何采样 action value:
从状态 ( s , a ) (s,a) ( s , a ) π k \pi_k π k
将 return 记为 g ( s , a ) g(s,a) g ( s , a ) g ( s , a ) g(s,a) g ( s , a ) G t G_t G t G t G_t G t q π k ( s , a ) = E [ G t ∣ S t = s , A t = a ] q_{\pi_k}(s,a)=\mathbb{E}[G_t \mid S_t=s,A_t=a] q π k ( s , a ) = E [ G t ∣ S t = s , A t = a ]
假设我们有一系列的 episode,就可以采样到一系列的 { g ( j ) ( s , a ) } \{g^{(j)}(s,a)\} { g ( j ) ( s , a )} q π k = E [ G t ∣ S t = s , A t = a ] ≈ 1 N ∑ i = 1 N g ( i ) ( s , a ) q_{\pi_k}=\mathbb{E}[G_t \mid S_t=s,A_t=a] \approx \frac{1}{N}\sum_{i=1}^N g^{(i)}(s,a) q π k = E [ G t ∣ S t = s , A t = a ] ≈ N 1 ∑ i = 1 N g ( i ) ( s , a )
也就是这样的思想:当 model 不可获得的时候,我们就使用 data 来代替 model
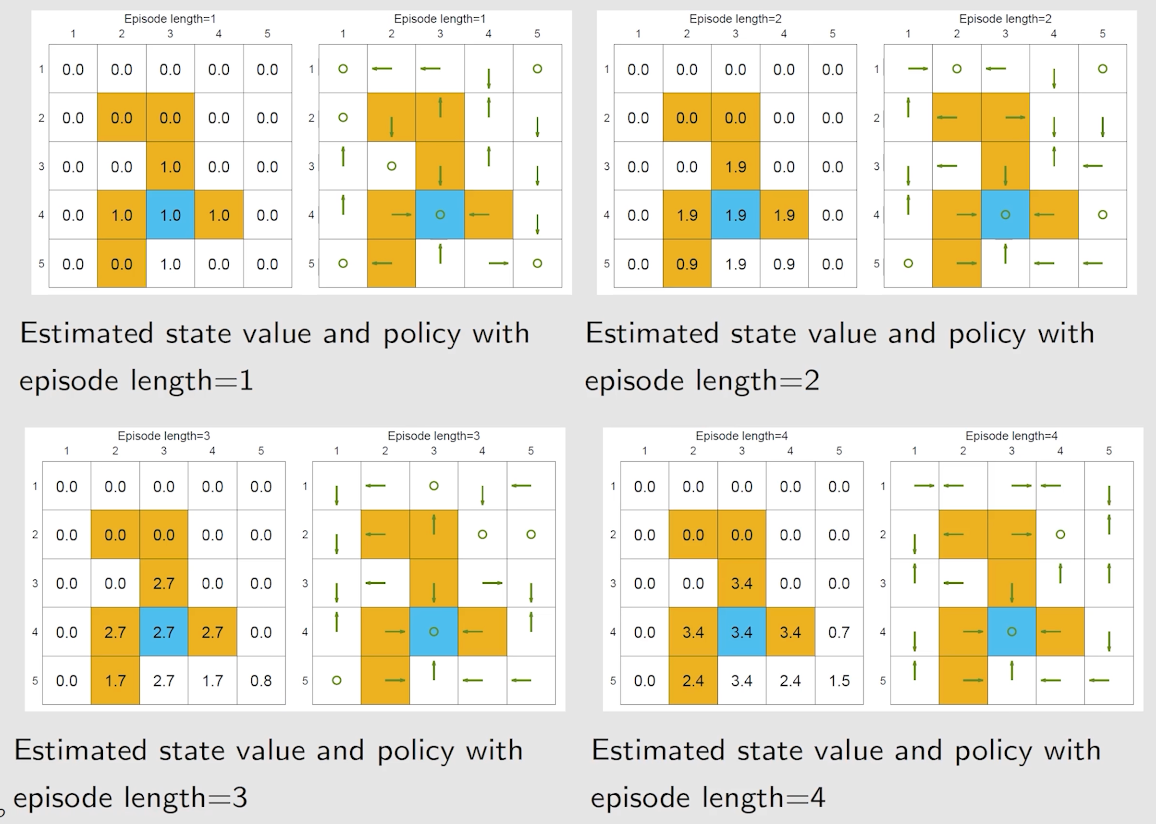
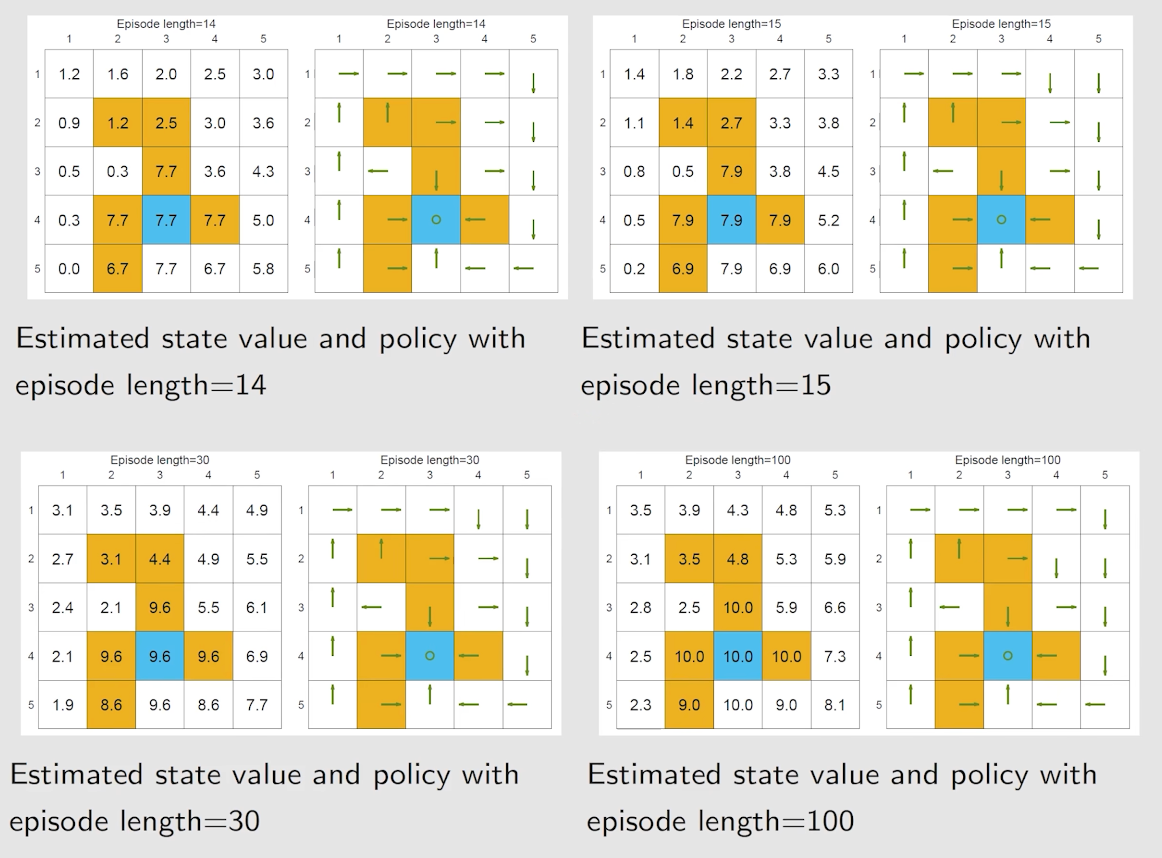
我们通过一个例子观察 episode length 对于策略的影响。
5 × 5 5 \times 5 5 × 5
Reward setting:r b o u n d a r y = − 1 , r f o r b i d d e n = − 10 , r t a r g e t = 1 , γ = 0.9 r_{boundary}=-1,\;r_{forbidden}=-10,\;r_{target}=1,\; \gamma=0.9 r b o u n d a r y = − 1 , r f or bi dd e n = − 10 , r t a r g e t = 1 , γ = 0.9
随着 episode length 的增长,policy 会发生如下变化:
可以看到,随着 episode length 变大,target 附近最佳的 policy 的范围变大。
每一个 s s s g ( s , a ) g(s,a) g ( s , a )
在实际中,episode length 需要足够大,但不需要无限大。
s 1 → a 2 s 2 → a 4 s 1 → a 2 s 2 → a 3 s 5 → a 1 ⋯ s_1 \xrightarrow{a_2} s_2
\xrightarrow{a_4} s_1
\xrightarrow{a_2} s_2
\xrightarrow{a_3} s_5
\xrightarrow{a_1} \cdots s 1 a 2 s 2 a 4 s 1 a 2 s 2 a 3 s 5 a 1 ⋯ 每当有一个 state-action 对 ( s , a ) (s,a) ( s , a )
在之前的算法中,我们都是采用这样一条 episode 去计算一个 return 并以此估计 q π ( s 1 , a 2 ) q_\pi(s_1,a_2) q π ( s 1 , a 2 )
我们可以采用下面的方式:
s 1 → a 2 s 2 → a 4 s 1 → a 2 s 2 → a 3 s 5 → a 1 ⋯ [ original episode ] s 2 → a 4 s 1 → a 2 s 2 → a 3 s 5 → a 1 ⋯ [ episode starting from ( s 2 , a 4 ) ] s 1 → a 2 s 2 → a 3 s 5 → a 1 ⋯ [ episode starting from ( s 1 , a 2 ) ] s 2 → a 3 s 5 → a 1 ⋯ [ episode starting from ( s 2 , a 3 ) ] s 5 → a 1 ⋯ [ episode starting from ( s 5 , a 1 ) ] \begin{array}{l l}
s_1 \xrightarrow{a_2} s_2
\xrightarrow{a_4} s_1
\xrightarrow{a_2} s_2
\xrightarrow{a_3} s_5
\xrightarrow{a_1} \cdots
& [\text{original episode}] \\[6pt]
s_2 \xrightarrow{a_4} s_1
\xrightarrow{a_2} s_2
\xrightarrow{a_3} s_5
\xrightarrow{a_1} \cdots
& [\text{episode starting from } (s_2, a_4)] \\[6pt]
s_1 \xrightarrow{a_2} s_2
\xrightarrow{a_3} s_5
\xrightarrow{a_1} \cdots
& [\text{episode starting from } (s_1, a_2)] \\[6pt]
s_2 \xrightarrow{a_3} s_5
\xrightarrow{a_1} \cdots
& [\text{episode starting from } (s_2, a_3)] \\[6pt]
s_5 \xrightarrow{a_1} \cdots
& [\text{episode starting from } (s_5, a_1)]
\end{array} s 1 a 2 s 2 a 4 s 1 a 2 s 2 a 3 s 5 a 1 ⋯ s 2 a 4 s 1 a 2 s 2 a 3 s 5 a 1 ⋯ s 1 a 2 s 2 a 3 s 5 a 1 ⋯ s 2 a 3 s 5 a 1 ⋯ s 5 a 1 ⋯ [ original episode ] [ episode starting from ( s 2 , a 4 )] [ episode starting from ( s 1 , a 2 )] [ episode starting from ( s 2 , a 3 )] [ episode starting from ( s 5 , a 1 )] 通过这种方式,我们可以估计 q π ( s 1 , a 2 ) , q π ( s 2 , a 4 ) , q π ( s 2 , a 3 ) , q π ( s 5 , a 1 ) , … q_\pi(s_1,a_2),q_\pi(s_2,a_4),q_\pi(s_2,a_3),q_\pi(s_5,a_1),\dots q π ( s 1 , a 2 ) , q π ( s 2 , a 4 ) , q π ( s 2 , a 3 ) , q π ( s 5 , a 1 ) , …
一条 episode 上可能会有多个相同的 visit。有两种方案供采用:
first-visit method:只计算一次,下次碰到相同的 visit 不计算
every-visit method:计算多次,碰到相同的 visit 依旧计算
面对何时更新策略的问题,也有两种不同的方案:
一种方案是收集所有的以当前 state-action pair 为起点的 episode 的return,计算平均值后更新。
另一种方案是在找到一个符合要求的 episode 后,计算 return 并立刻更新,作为近似的 action value。
简称为 GPI。It refers to the general idea or framework of switching between policy-evaluation and policy-improvement processes.
许多 model-based 和 model-free 算法都可以归到这个框架里。
需要注意的是,在这个算法中,是从后向前计算 return value 的。
理论上,我们需要确保每一个 state-action 对都能被访问。
由于在一条 episode 上,不总是所有的 state-action 对都能被访问,因此总会存在多条 episode,它们的开头 state 不一样。
这点体现在实际上就是我们需要不断改变机器的起始位置,这点非常麻烦。下一个算法可以解决这个问题。
我们称一个策略是 soft 的,若其采取任何 action 的可能性是大于 0 的。
有了 soft policy,我们就可以确保存在一条足够长的 episode,其可以访问到所有的 state-action 对。此时,可以移除 exploring starts。
π ( a ∣ s ) = { 1 − ε ∣ A ( s ) ∣ ( ∣ A ( s ) ∣ − 1 ) , for the greedy action , ε ∣ A ( s ) ∣ , for the other ∣ A ( s ) ∣ − 1 actions . \pi(a \mid s)
=
\begin{cases}
1 - \dfrac{\varepsilon}{|\mathcal{A}(s)|} \left(|\mathcal{A}(s)| - 1\right),
& \text{for the greedy action}, \\[10pt]
\dfrac{\varepsilon}{|\mathcal{A}(s)|},
& \text{for the other } |\mathcal{A}(s)| - 1 \text{ actions}.
\end{cases} π ( a ∣ s ) = ⎩ ⎨ ⎧ 1 − ∣ A ( s ) ∣ ε ( ∣ A ( s ) ∣ − 1 ) , ∣ A ( s ) ∣ ε , for the greedy action , for the other ∣ A ( s ) ∣ − 1 actions .
选择 greedy action 的概率总是比选择非 greedy action 的概率要大的。因为 1 − ε ∣ A ( s ) ∣ ( ∣ A ( s ) ∣ − 1 ) = 1 − ε + ε ∣ A ( s ) ∣ ≥ ε ∣ A ( s ) ∣ 1-\frac{\varepsilon}{|\mathcal{A}(s)|}(|\mathcal{A}(s)|-1)=1-\varepsilon+\frac{\varepsilon}{|\mathcal{A}(s)|} \geq \frac{\varepsilon}{|\mathcal{A}(s)|} 1 − ∣ A ( s ) ∣ ε ( ∣ A ( s ) ∣ − 1 ) = 1 − ε + ∣ A ( s ) ∣ ε ≥ ∣ A ( s ) ∣ ε
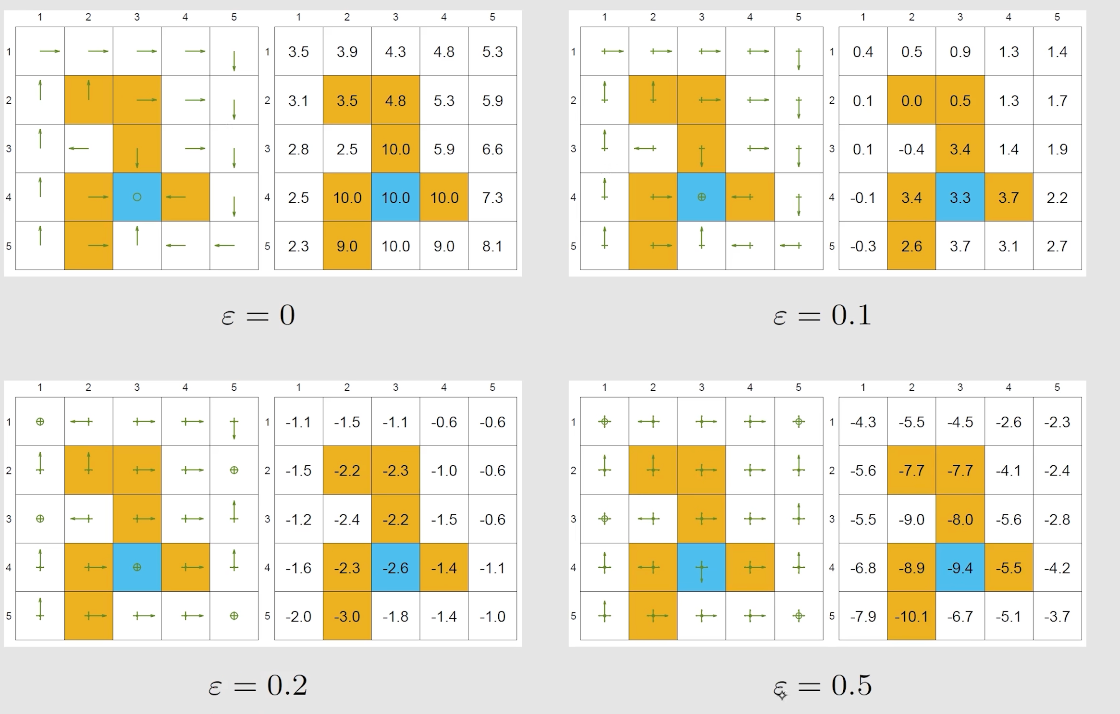
ε \varepsilon ε
当 ε = 0 \varepsilon = 0 ε = 0
当 ε = 1 \varepsilon=1 ε = 1
在 MC-based 和 MC Exploring Starts 算法中,policy improvement 阶段如下:
π k + 1 ( s ) = arg max π ∈ Π ∑ a π ( a ∣ s ) q π k ( s , a ) . \pi_{k+1}(s)
=
\arg\max_{\pi \in \Pi}
\sum_{a} \pi(a \mid s)\, q_{\pi_k}(s,a). π k + 1 ( s ) = arg π ∈ Π max a ∑ π ( a ∣ s ) q π k ( s , a ) . 其中 Π \Pi Π
根据之前的内容可知,最优策略就是:
π k + 1 ( a ∣ s ) = { 1 , a = a k ∗ 0 , a ≠ a k ∗ where a k ∗ = arg max a q π k ( s , a ) \pi_{k+1}(a \mid s)
=
\begin{cases}
1, & a = a_k^* \\
0, & a \ne a_k^*
\end{cases}
\\
\text{where }
a_k^*
=
\arg\max_{a} q_{\pi_k}(s,a) π k + 1 ( a ∣ s ) = { 1 , 0 , a = a k ∗ a = a k ∗ where a k ∗ = arg a max q π k ( s , a ) 我们对 policy improvement 阶段进行更改:
π k + 1 ( s ) = arg max π ∈ Π ε ∑ a π ( a ∣ s ) q π k ( s , a ) \pi_{k+1}(s)
=
\arg\max_{\pi \in \Pi_{\varepsilon}}
\sum_{a} \pi(a \mid s)\, q_{\pi_k}(s,a) π k + 1 ( s ) = arg π ∈ Π ε max a ∑ π ( a ∣ s ) q π k ( s , a ) 其中 Π ε \Pi_\varepsilon Π ε ε \varepsilon ε
最优策略为:
π k + 1 ( a ∣ s ) = { 1 − ∣ A ( s ) ∣ − 1 ∣ A ( s ) ∣ ε , a = a k ∗ ε ∣ A ( s ) ∣ , a ≠ a k ∗ \pi_{k+1}(a \mid s)
=
\begin{cases}
1 - \dfrac{|\mathcal{A}(s)| - 1}{|\mathcal{A}(s)|}\,\varepsilon,
& a = a_k^* \\[10pt]
\dfrac{\varepsilon}{|\mathcal{A}(s)|},
& a \ne a_k^*
\end{cases} π k + 1 ( a ∣ s ) = ⎩ ⎨ ⎧ 1 − ∣ A ( s ) ∣ ∣ A ( s ) ∣ − 1 ε , ∣ A ( s ) ∣ ε , a = a k ∗ a = a k ∗
ε \varepsilon ε 缺点在于其得到的最优策略不一定是全局的最优策略了(因为其仅仅是ε \varepsilon ε
实际中我们可以逐步控制 ε \varepsilon ε
注意到当 ε = 0.1 \varepsilon=0.1 ε = 0.1 ε = 0 \varepsilon=0 ε = 0
可以看到,当 ε \varepsilon ε ε \varepsilon ε