操作系统
Lec11: File System Implementation
文件系统分层结构、磁盘上的元数据组织、目录实现、空闲空间管理、分配方法,以及效率与性能。
File System Structure
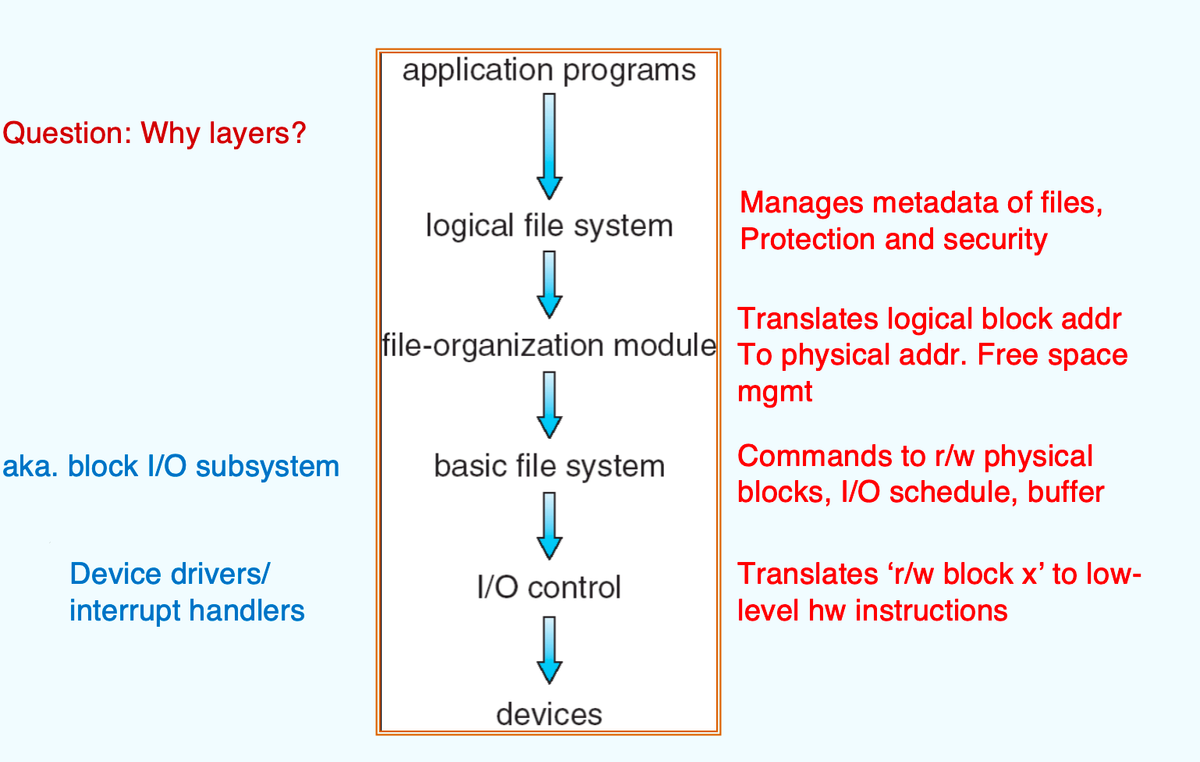
- I/O control:
- 翻译高级命令为底层指令
- Basic File System:
- 只需向适当设备驱动程序发送通用命令,以读取和写人磁盘的物理块
- File-Organization Module:
- 翻译逻辑块地址为物理块地址
- 管理可用空间
- Logical File System:
- 管理元数据信息。元数据包括文件系统的所有结构,而不包括实际数据(或文件内容)
- 逻辑文件系统也负责保护
采用分层的文件系统有很多好处,比如:
- 分层,更独立,每个文件系统可以有自己的逻辑文件系统和文件组织模块
- 隐藏下层细节
但是,分层也会增加系统开销,并导致性能降低。
The implementation of File system
想要实现一个文件系统,显而易见的,我们需要采用多个磁盘和内存的结构。
Data Structures Used to Implement FS
- Disk structures
- Boot control block (per volume)
- 每个卷(分区)的开头。它包含该卷引导操作系统所需的指令(引导装入程序)。如果该卷没有操作系统,此块可能为空。
- Volume control block per volume (superblock in Unix)
- (每个卷的)卷控制块(volumecontrolblock)包括卷(或分区)的详细信息,如分区的块的数量、块的大小、空闲块的数量和指针、空闲的FCB数量和FCB指针等。
- UFS称之为超级块(superblock),而在NTFS中它存储在主控文件表(master filetable)中。
- Directory structure per file system
- 存储文件名及其对应的 FCB 指针(或索引节点号)。它负责组织文件系统(如文件夹层次结构)。
- Per-file FCB (inode in Unix)
- 在 Unix 中称为 Inode。
- 每个文件唯一对应一个 FCB。它包含文件的元数据:
- 文件许可权限、所有者、大小。
- 数据块在磁盘上的物理位置指针
- Boot control block (per volume)
内存中的信息用于管理文件系统并通过缓存来提高性能。
这些数据在安装文件系统时被加载,在文件系统操作期间被更新,在卸载时被丢弃。
- In-memory structures (see fig)
- In-memory mount table about each mounted volume
- 记录所有已挂载(Mount)的卷的信息。每当一个磁盘分区被挂载时,系统会将该卷的信息存入此表,以便操作系统知道如何访问不同的分区。
- Directory cache for recently accessed directories
- 运用了时间局部性原理
- System-wide open-file table
- 包含整个系统中所有进程打开的文件。
- 每个条目包含文件的 FCB 副本(即 inode 信息)、打开计数器(记录有多少个进程在使用它)以及文件的状态。
- Per-process open-file table
- 每个进程都有一个
- 内容:条目指向“系统级打开文件表”中的对应项。它还包含:
- 文件描述符 (File Descriptor):在 Unix 中是 int 类型的 ID。
- 当前文件指针 (Current-file-position pointer):记录该进程读/写到文件的哪个位置。
- In-memory mount table about each mounted volume
File Control Block
如果把文件系统比作一个大型图书馆,那么 FCB 就是每一本书的“图书卡”或“身份证”。它包含了操作系统管理文件所需要的所有元数据(Metadata),但不包含文件的具体内容。
当操作系统提到一个“文件”时,它实际上是在操作这个文件的 FCB。一个典型的 FCB 包含以下信息:

为了创建新的文件,应用程序调用逻辑文件系统。逻辑文件系统知道目录结构的格式;它会分配一个新的FCB。(或者如果文件系统的实现在文件系统创建时已经创建了所有的FCB,则可从空闲的FCB集合中分配一个可用的FCB。)
然后,系统将相应的目录读到内存,使用新的文件名和FCB进行更新,并将它写回到磁盘。
In-memory File System Structures
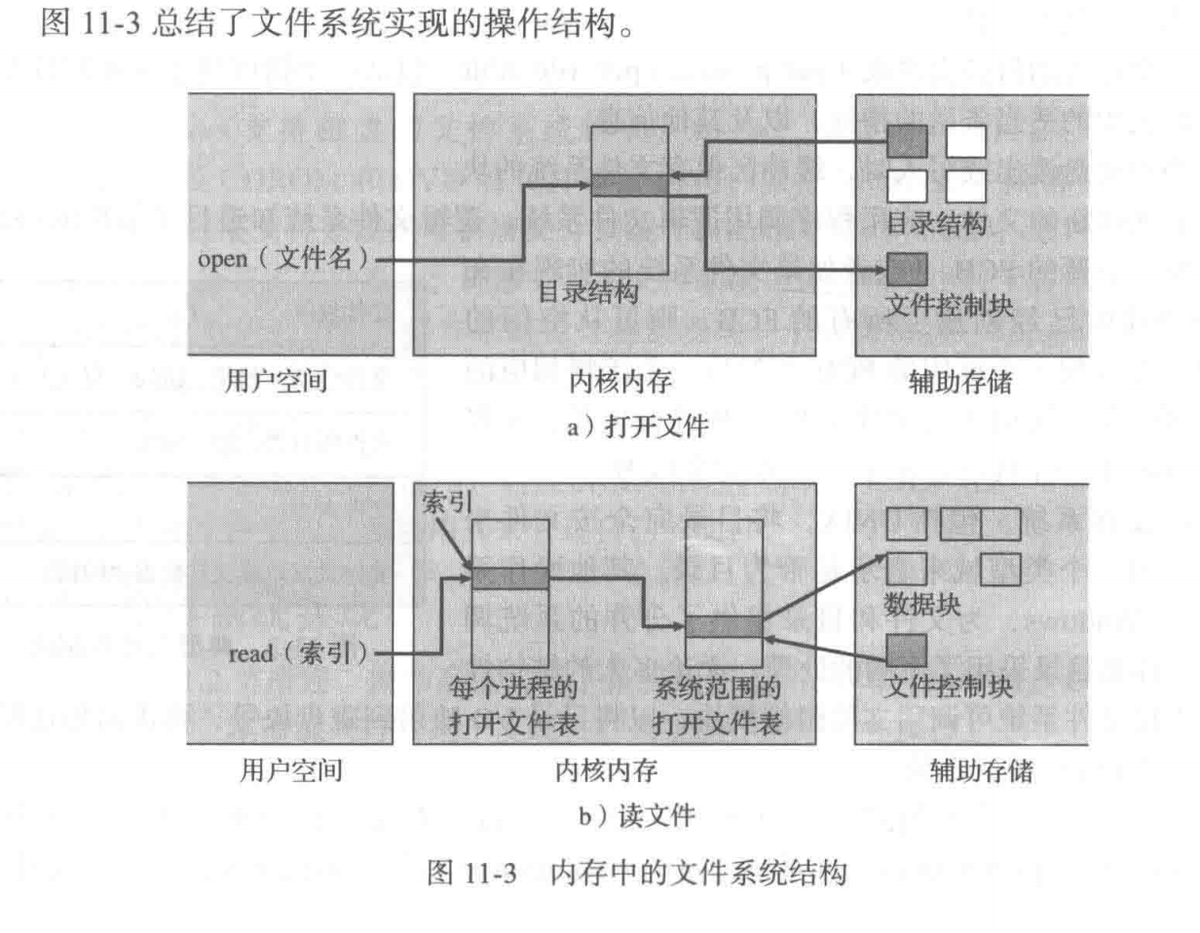
- 打开文件
open():- 系统首先搜索目录结构(通常在内存缓存中)以获取文件的 FCB。
- 将 FCB 复制到系统范围打开文件表。
- 在进程表中创建一个条目并返回一个文件描述符(UNIX)或文件句柄(Windows)。
- 读写文件
read()/write():- 一旦文件打开,系统通过文件描述符直接定位到内存中的 FCB 指针。
- 使用进程表中的“当前位置指针”确定读写位置,无需再次搜索目录。
- 关闭文件
close():- 删除进程表条目,递减系统表的打开计数。
- 当计数归零时,若元数据有更新,将其同步回磁盘并从系统表中删除该项。
分区和安装
- 磁盘分区与布局
- 物理划分:一个磁盘可以划分为多个分区,也可以通过 RAID 技术让一个卷跨越多个磁盘。
- 分区类型:
- “原始”磁盘 (Raw Disk):不含文件系统,常用于 UNIX 交换空间、数据库存储或存储 RAID 的元数据(如位图)。
- “熟的”磁盘:包含已经格式化好的文件系统。
- 系统引导机制 (Booting)
- 引导加载程序 (Boot Loader):由于引导时文件系统尚未加载,引导信息通常以一系列连续块的形式存在。
- 功能:引导加载程序负责定位并加载操作系统内核到内存中,并支持双引导(在同一系统中选择启动不同的操作系统)。
- 文件系统的挂载 (Mounting)
- 根分区 (Root Partition):包含内核和其他系统文件,在系统启动时首先被安装(挂载)。
- 验证与记录:系统在挂载卷时会验证其文件系统格式的有效性,并在内存中的安装表 (Mount Table) 中记录已安装的文件系统及其类型。

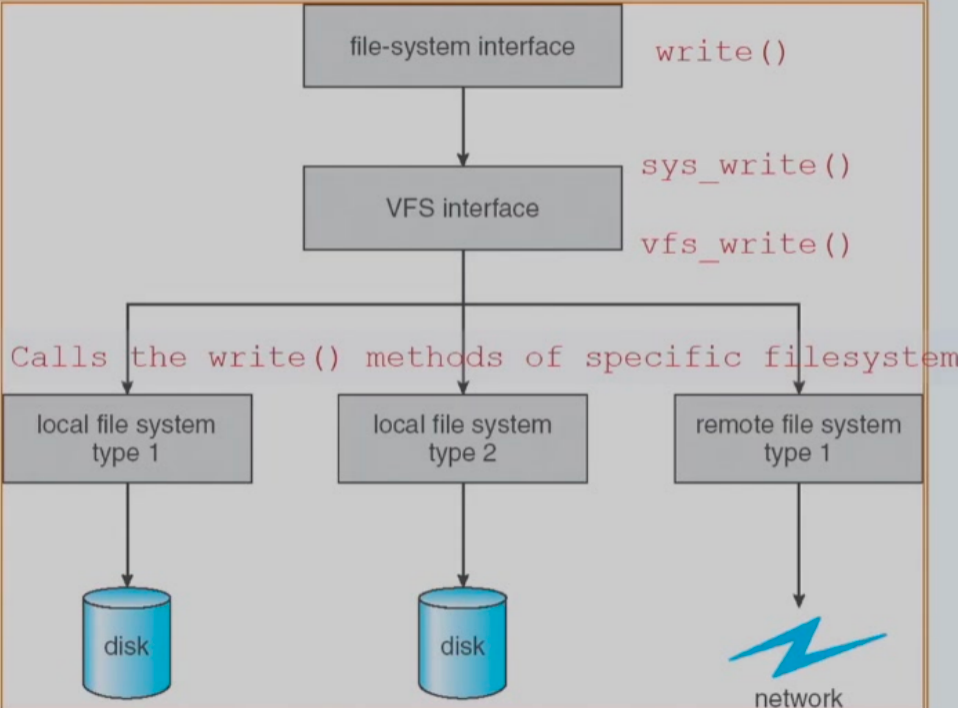
Virtual File Systems
- 第一层为文件系统接口,基于open()、read()、write()和close()调用及文件描述符。
- Virtual File Systems (VFS) provide an object-oriented way of implementing filesystems. VFS is NOT a disk file system!
- VFS allows the same system call interface (the APl) to be used for different typesof file systems.
- The APl is to the VFS interface, rather than any specific type of file system.
- Defines a network-wide unique structure called vnode.
- VFS基于称为虚拟节点或V节点(vnode)的文件表示结构,它包含一个数字指示符以唯一表示网络上的一个文件。(在一个文件系统内,UNIXinode是唯一的。)
Directory Implenmentation
接下来来讨论目录的实现。
- Linear list of file names with pointer to the data blocks.
- simple to program
- time-consuming to execute
- Hash Table - linear list with hash data structure.
- decreases directory search time
- collisions-situations where two file names hash to the same location
- 两个hash值一样,产生碰撞
- fixed size-can use chained-overflow hash table
- 使用溢出链接(chain-overflow)的哈希表,哈希表每个条目可以是链表而不是单个值
- Or rehashing to another larger hash table
Allocation Methods
接下来,我们来讨论如何为文件分配磁盘空间:
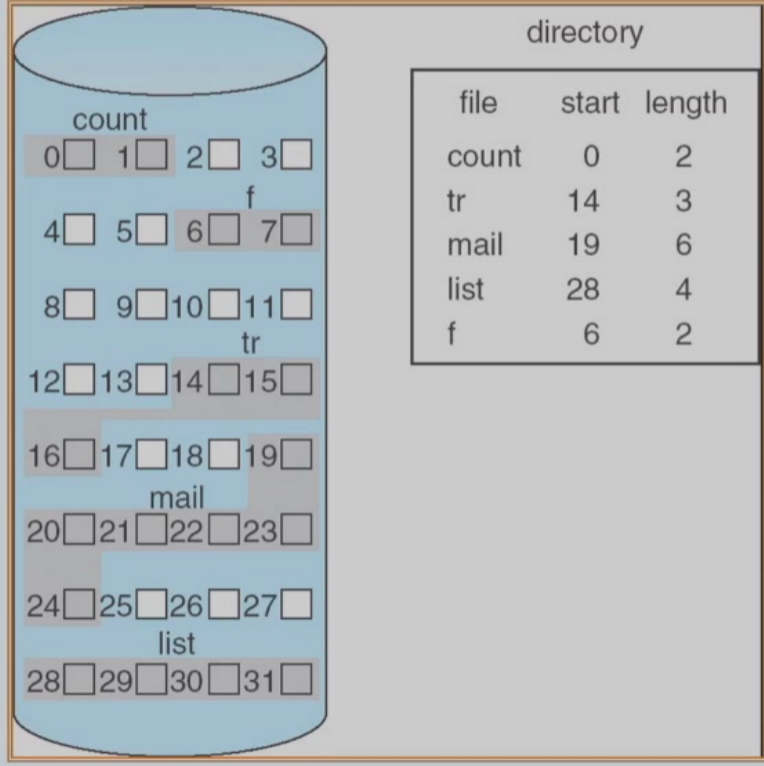
Contiguous Allocation
- Each file occupies a set of contiguous blocks on the disk
- Simple - only starting location (block #) and length(number of blocks) are required
- Random access supported
- 连续分配文件的访问非常容易。对于顺序访问,文件系统会记住上次引用的块的磁盘地址,如需要可读入下一块。对于直接访问一个文件的从块b开始的第i块,可以直接访问块b+i。因此,连续分配支持顺序访问和直接访问。
- Wasteful of space (dynamic storage-allocationproblem)
- 会产生空洞
- Files cannot grow
- 文件大小不能增长
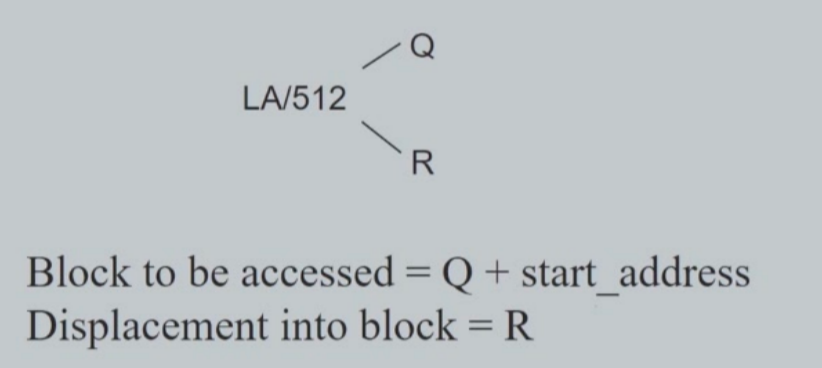
- Mapping from logical to physical

为了解决上面的两个问题,我们可以考虑采用 Extent-Based Systems:
- Many newer file systems use a modified contiguous allocation scheme
- Extent-based file systems allocate disk blocks in extents
- An extent is a contiguous block of disks
- Extents are allocated for file allocation
- A file consists of one or more extents. The next extent isrecorded as a link
- Some file systems support dynamic block size allocation:Btrfs,ReFS etc.
中文解释如下:

Linked Allocation
链接分配(linkedallocation)解决了连续分配的所有问题。
- Each file is a linked list of disk blocks: blocks may bescattered anywhere on the disk.
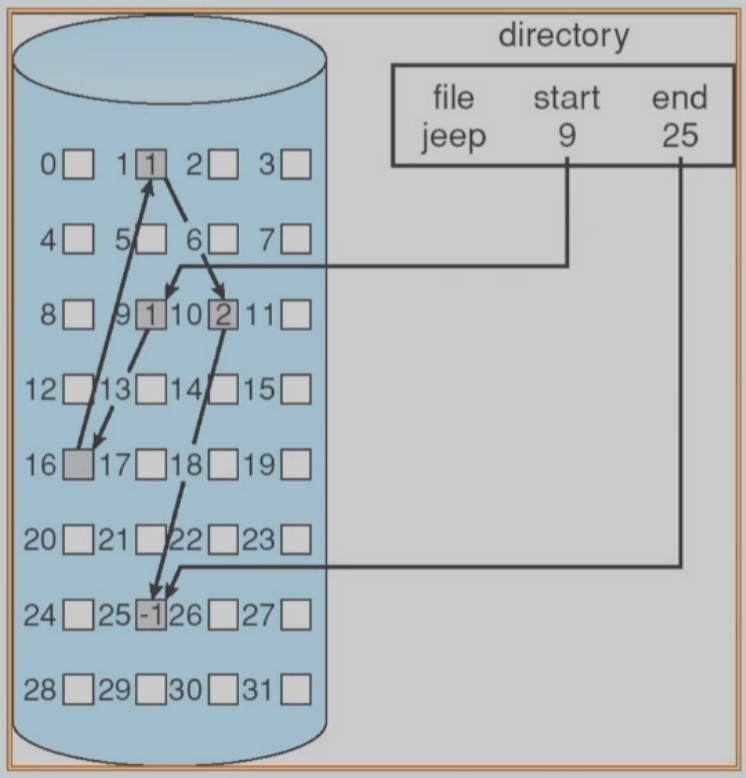
- Simple-need only starting address
- Free-space management system - no waste of space
- No random access,poor reliability
- 只能顺序访问
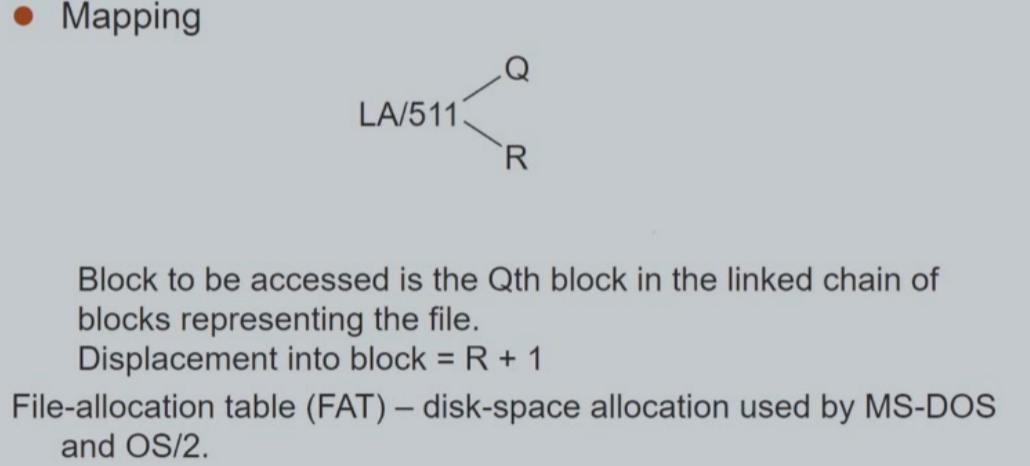

FAT
这是链接分配的一种变种,将==所有块的指针提取出来放在卷开头的磁盘表格中==。
FAT的使用与链表相同。目录条目包含文件首块的块号。通过这个块号索引的表条目包含文件的下一块的块号。这条链会继续下去,直到最后一块;而最后一块的表条目的值为文件结束值。未使用的块用0作为表条目的值来表示。
为文件分配一个新块只要简单找到第一个值为0的FAT条目,用新块的地址替换前面文件结束值,用文件结束值替代0。
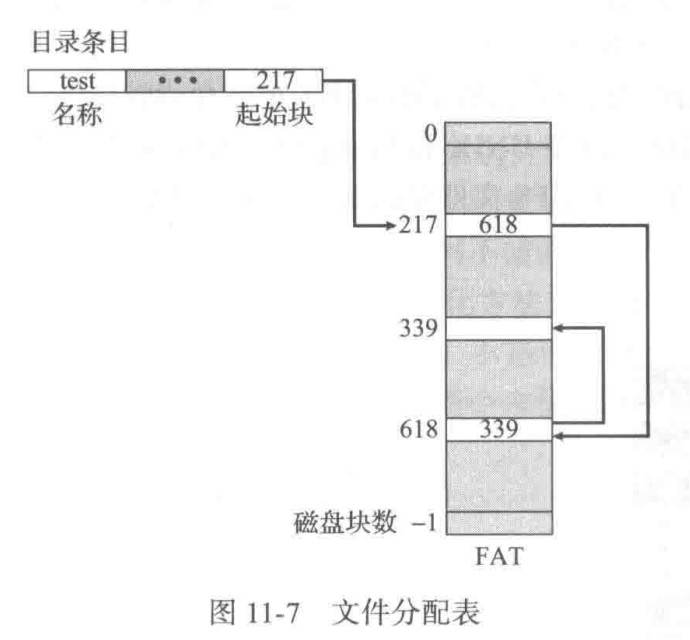
Index allocation
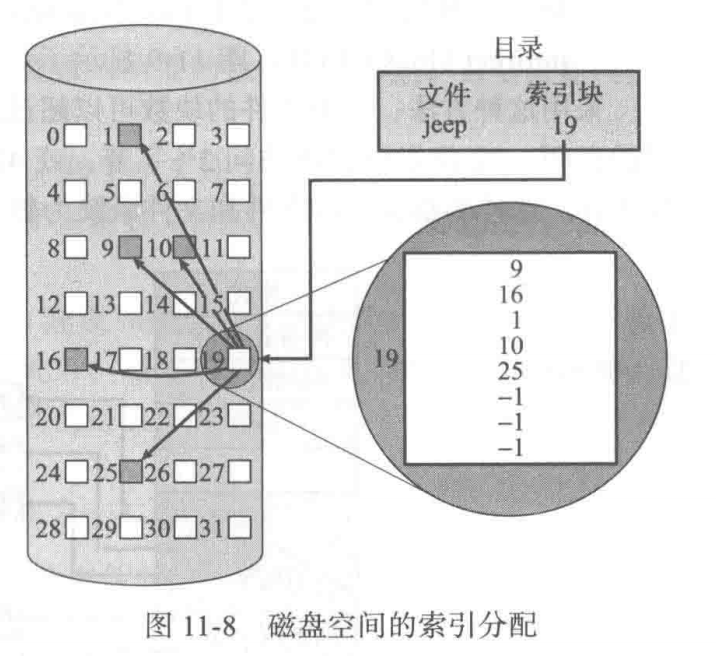
- 每个文件都有自已的索引块。
- 这是一个磁盘块地址的数组。
- 索引块的第i个条目指向文件的第i个块。
- 目录包含索引块的地址。
- 当查找和读取第i个块时,采用第i个索引块条目的指针。
当创建文件时,索引块的所有指针都设为null。当首次写入第i块时,先从空闲空间管理器中获得一块,再将其地址写到索引块的第i个条目。
- Need index table (analogous to page table)
- Random access
- Dynamic access without external fragmentation(没有外部碎片),but have overhead of index block.
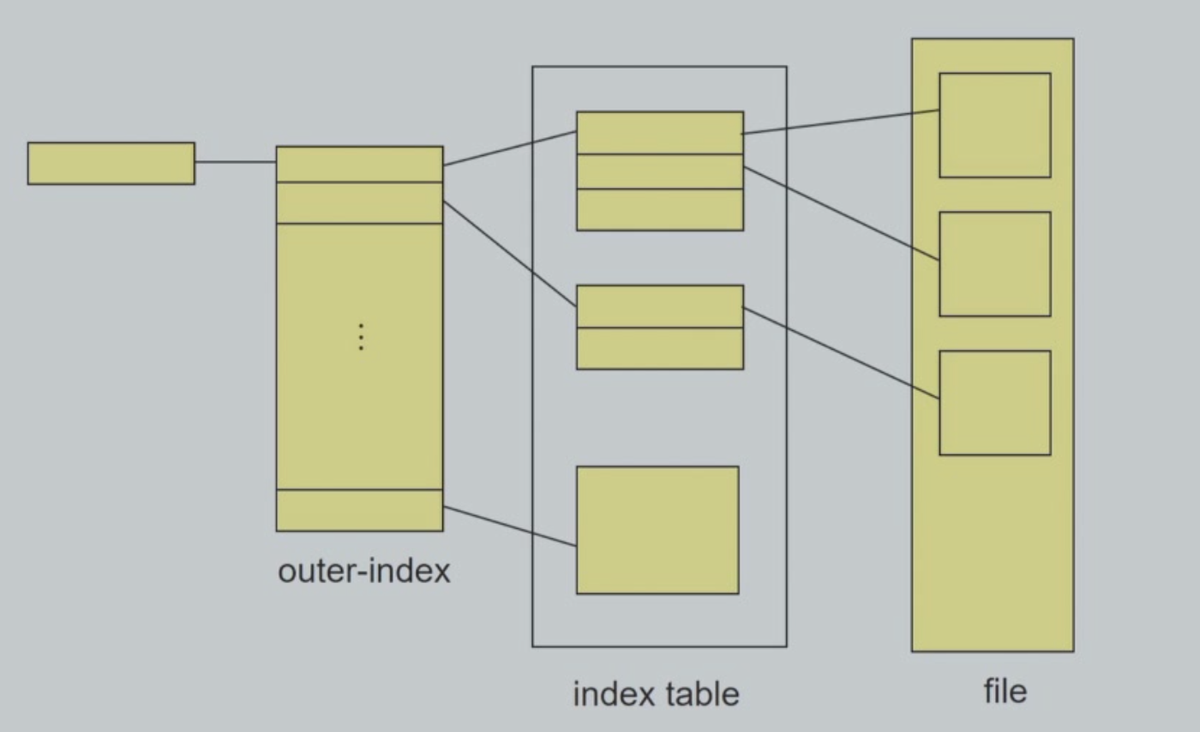
为了解决一个文件过大而无法用一个索引块来索引的情况,可以使用以下方法:
- Link Schema(链接方案):一个索引块通常为一个磁盘块。因此,它本身能直接读写。为了支持大的文件,可以将多个索引块链接起来。例如,一个索引块可以包括一个含有文件名的头部和一组头100个磁盘块的地址。下一个地址(索引块的最后一个字)为nu11(对于小文件),或者另一个索引块的指针(对于大文件)。
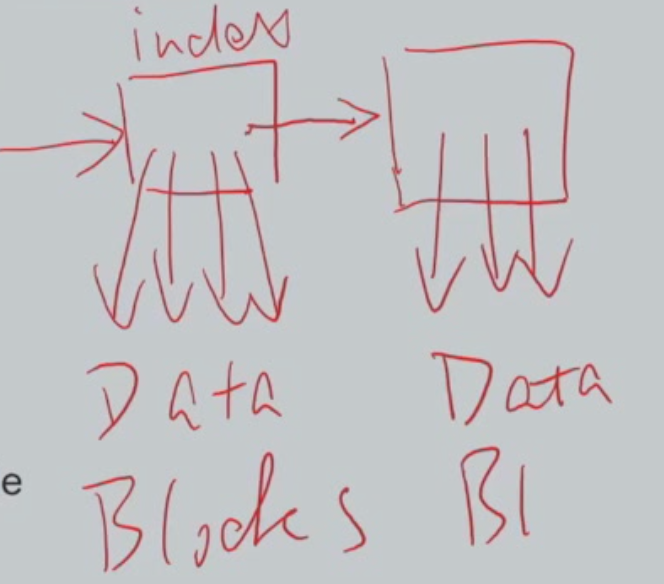
- Two-level index(多级索引):类似于树的结构,每层索引一级一级下来:
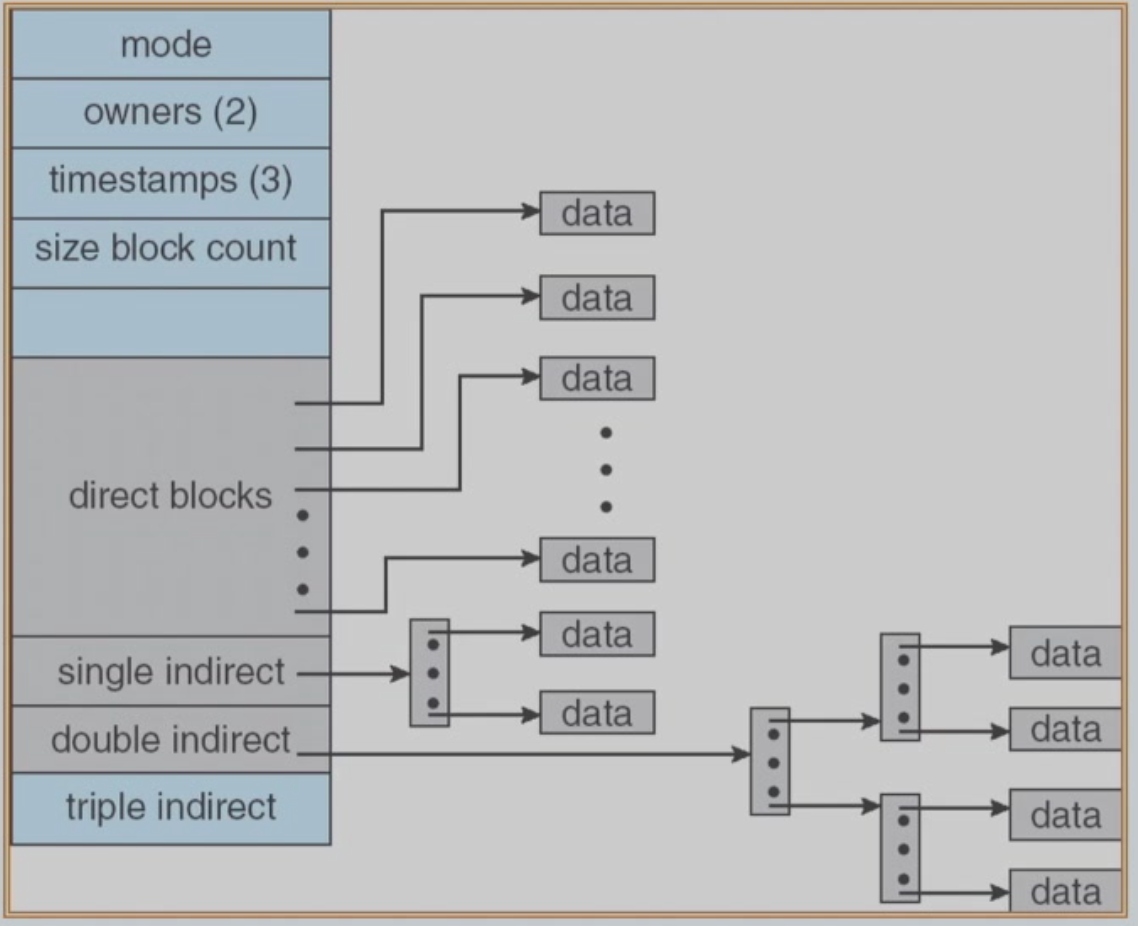
- Combine Schema(组合方案):将索引块的前几个指针存在文件的inode中。这些指针的前12个指向直接块。接下来的3个指针指向间接块。第一个指向一级间接块。第二个指向二级间接块。最后一个指针为三级间接块指针。
Free-Space Management
Bit Vector
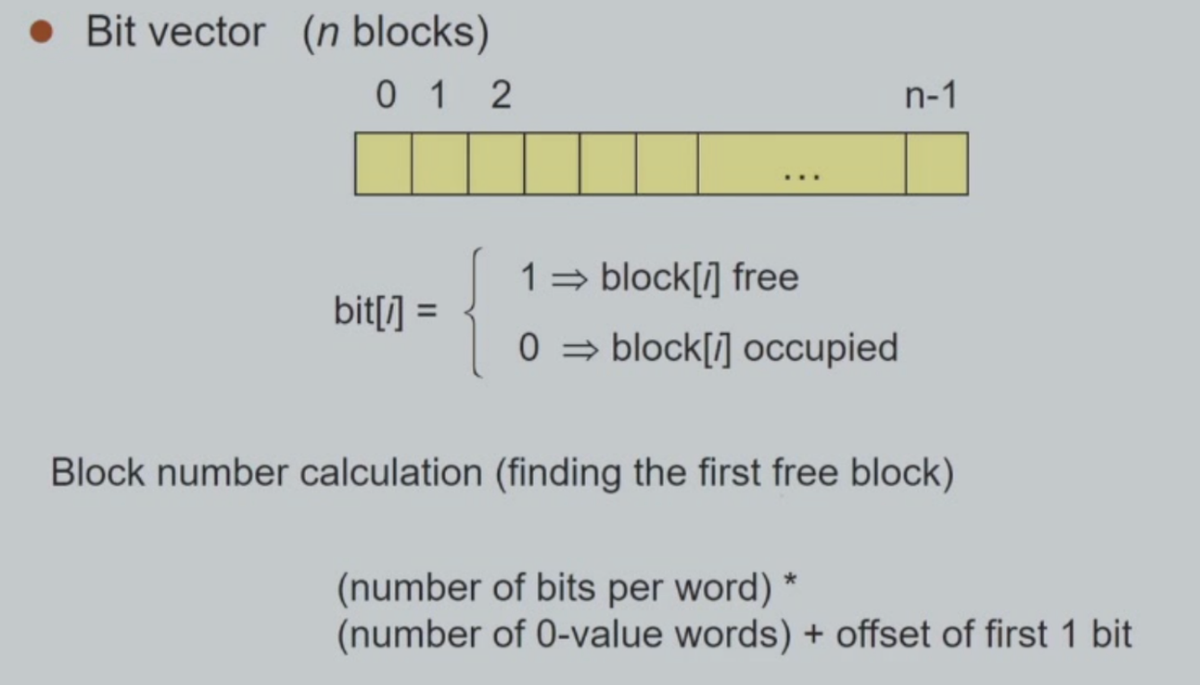
这个方法很简单,唯一需要注意的是下面的计算公式。我们举个例子来说明:

Ex:如何计算位图(Bit Map / Bit Vector)管理磁盘空闲空间时所需要的额外空间开销。

Linked list
- Cannot get contiguous space easily
- But basically can work(FAT)
- No waste of space
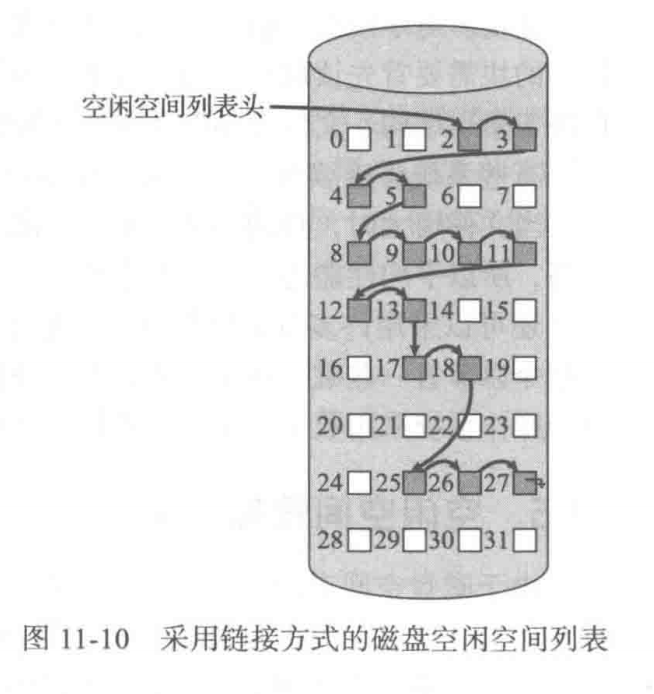
Grouping
- Addresses of the n free blocks are stored in the first block.
- The first n-1 blocks are actually free. The last block contains addresses of another n free blocks
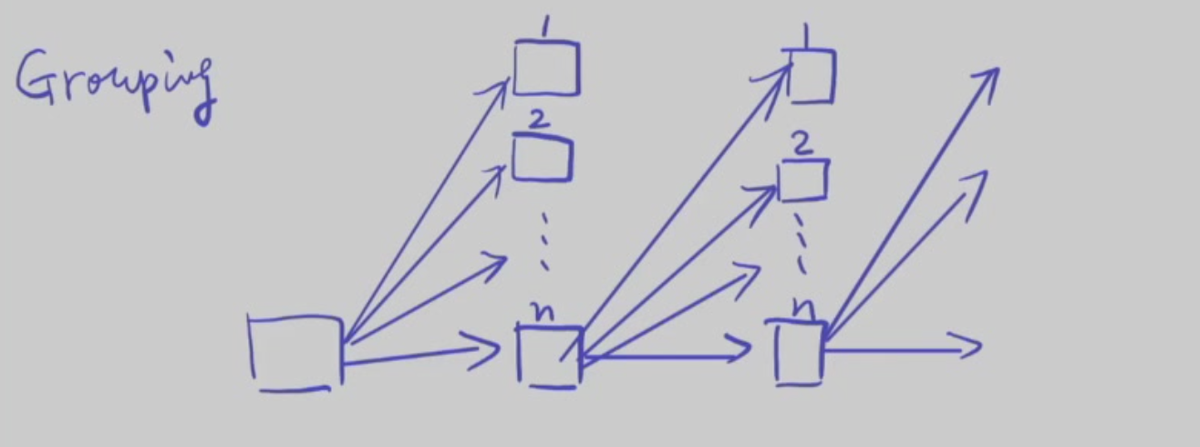
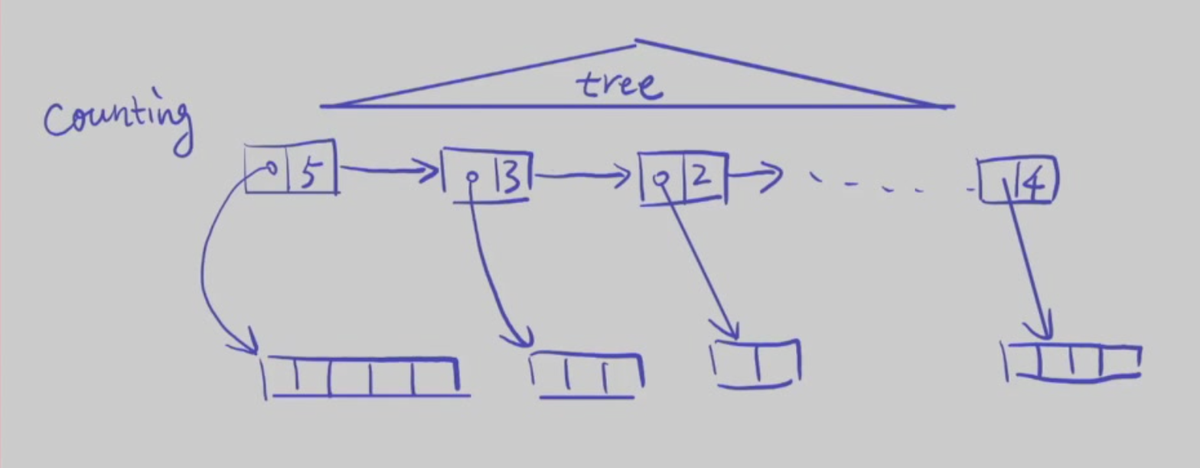
Counting
- Address of the first free block and number n contiguous blocks
Efficiency and Performance
- Efficiency dependent on:
- disk allocation and directory algorithms
- types of data kept in file's directory entry (for example “last write date” isrecorded in directory)
- Generally,every data item has tobe considered forits effect.
- Performance
- disk cache-separate section of main memory for frequently used blocks
- free-behind and read-ahead -techniques to optimize sequential access
- free-behind:在访问过一个块后,系统认为前一个块几乎不可能访问,就释放掉了
- read-behind:在访问一个块时,系统会认为你很快就会访问后一个块,于是提前读进来
- improve PC performance by dedicating section of memory asvirtual disk,or RAM disk
Page Cache
注意:这里buffer的地方不是在输入输出那里的buffer,而是在logical file system这里的
- A page cache caches pages rather than disk blocks using virtual memory techniques
- Memory-mapped I/O uses a page cache
- Routine I/O through the file system uses the buffer (disk) cache
- This leads to the following figure

Written by
ZZC
每天研究怎么摸鱼的神人
Comments
评论功能即将上线