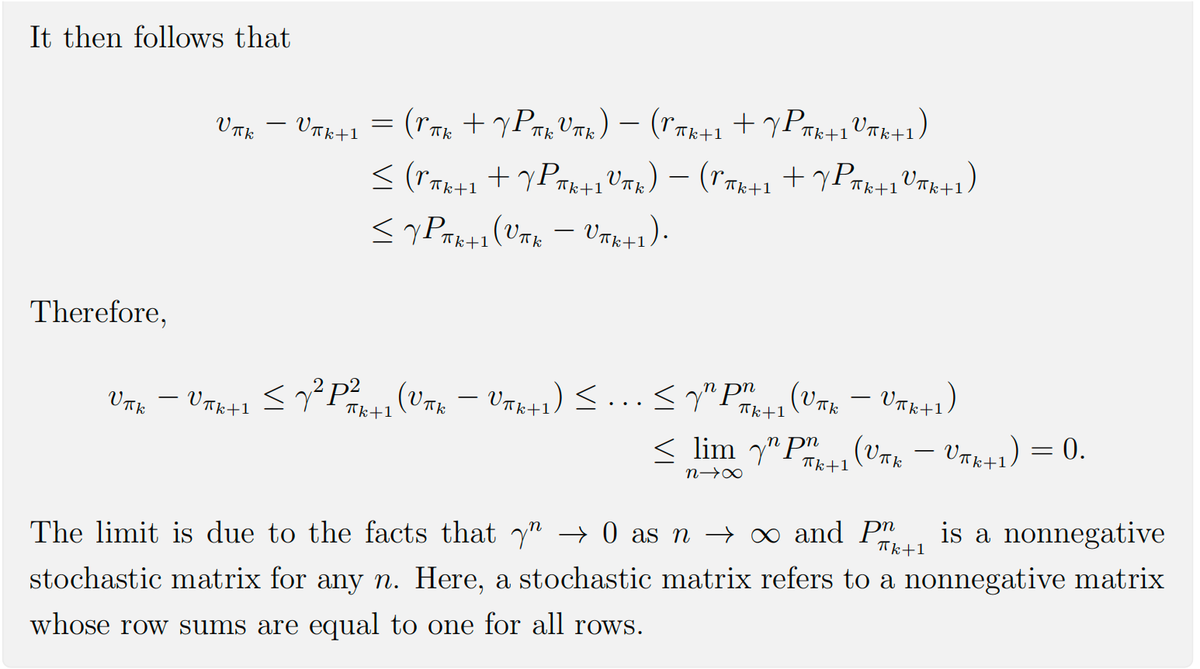这一节的数学基础其实就是上节课介绍过的公式:
v k + 1 = f ( v k ) = max π ( r π + γ P π v k ) v_{k+1}=f(v_k)=\max_\pi(r_\pi+\gamma P_\pi v_k) v k + 1 = f ( v k ) = π max ( r π + γ P π v k ) 对于这个公式的计算,我们可以将其分为两个步骤:首先我们要处理右边的关于策略 π \pi π
v k v_{k} v k v k + 1 = max π ( r π + γ P π v k ) v_{k+1}=\max_\pi(r_\pi+\gamma P_\pi v_k) v k + 1 = max π ( r π + γ P π v k ) v v v
这一步是为了求出最优的策略的:
π k + 1 = arg max π ( r π + γ P π v k ) \pi_{k+1}=\arg \max_\pi(r_\pi+\gamma P_\pi v_k) π k + 1 = arg π max ( r π + γ P π v k ) 也就是:
π k + 1 ( s ) = arg max π ∑ a π ( a ∣ s ) ( ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v k ( s ′ ) ) ⏟ q k ( s , a ) , s ∈ S \pi_{k+1}(s) = \arg \max_{\pi} \sum_{a} \pi(a|s) \underbrace{\left( \sum_{r} p(r|s, a)r + \gamma \sum_{s'} p(s'|s, a)v_{k}(s') \right)}_{q_k(s,a)}, \quad s \in \mathcal{S} π k + 1 ( s ) = arg π max a ∑ π ( a ∣ s ) q k ( s , a ) ( r ∑ p ( r ∣ s , a ) r + γ s ′ ∑ p ( s ′ ∣ s , a ) v k ( s ′ ) ) , s ∈ S 根据之前的经验,我们知道,想要到达最好的策略的话,就要:
π k + 1 ( a ∣ s ) = { 1 a = a k ∗ ( s ) 0 a ≠ a k ∗ ( s ) \pi_{k+1}(a|s) = \begin{cases}
1 & a = a_k^*(s) \\
0 & a \neq a_k^*(s)
\end{cases} π k + 1 ( a ∣ s ) = { 1 0 a = a k ∗ ( s ) a = a k ∗ ( s ) 此时:
a k ∗ ( s ) = arg max a q k ( a , s ) a_k^*(s) = \arg \max_{a} q_k(a, s) a k ∗ ( s ) = arg a max q k ( a , s ) 我们称 π k + 1 \pi_{k+1} π k + 1
这一步是为了求出 state value:
v k + 1 = r π k + 1 + γ P π k + 1 v k v_{k+1}=r_{\pi_{k+1}}+\gamma P_{\pi_{k+1}} v_k v k + 1 = r π k + 1 + γ P π k + 1 v k 需要注意的是,上面 value update 中的 v k v_k v k
展开公式,得到:
v k + 1 ( s ) = ∑ a π k + 1 ( a ∣ s ) ( ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v k ( s ′ ) ) ⏟ q k ( s , a ) , s ∈ S v k + 1 ( s ) = ∑ a π k + 1 ( a ∣ s ) q k ( s , a ) v_{k+1}(s) = \sum_{a} \pi_{k+1}(a|s) \underbrace{\left( \sum_{r} p(r|s, a)r + \gamma \sum_{s'} p(s'|s, a)v_{k}(s') \right)}_{q_k(s,a)}, \quad s \in \mathcal{S} \\
v_{k+1}(s)=\sum_a \pi_{k+1}(a \mid s)q_k(s,a) v k + 1 ( s ) = a ∑ π k + 1 ( a ∣ s ) q k ( s , a ) ( r ∑ p ( r ∣ s , a ) r + γ s ′ ∑ p ( s ′ ∣ s , a ) v k ( s ′ ) ) , s ∈ S v k + 1 ( s ) = a ∑ π k + 1 ( a ∣ s ) q k ( s , a ) 根据上面的最优策略的选择,我们知道:
v k + 1 ( s ) = max a q k ( a , s ) v_{k+1}(s) = \max_{a} q_k(a, s) v k + 1 ( s ) = a max q k ( a , s ) Value iteration algorithm 算法如下所示:
正如名称所示,在这个方法中,我们更关注 policy 的衡量与优化,分为两个阶段:policy evaluation(PE)、policy improvement(PI)。
在这一步中,我们需要去衡量(计算)当前策略的 state value 有多好:
v π k = r π k + γ P π k v π k v_{\pi_k} = r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k} v π k = r π k + γ P π k v π k v π k v_{\pi_k} v π k
我们可以使用 Iteration solution 的方法来计算 v π k v_{\pi_k} v π k
v π k ( j + 1 ) = r π k + γ P π k v π k ( j ) , j = 0 , 1 , 2 , … v π k ( j + 1 ) ( s ) = ∑ a π k ( a ∣ s ) ( ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π k ( j ) ( s ′ ) ) , s ∈ S v_{\pi_k}^{(j+1)} = r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k}^{(j)}, \quad j = 0, 1, 2, \dots \\
v_{\pi_k}^{(j+1)}(s) = \sum_a \pi_k(a|s) \left( \sum_r p(r|s, a)r + \gamma \sum_{s'} p(s'|s, a) v_{\pi_k}^{(j)}(s') \right), \quad s \in \mathcal{S} v π k ( j + 1 ) = r π k + γ P π k v π k ( j ) , j = 0 , 1 , 2 , … v π k ( j + 1 ) ( s ) = a ∑ π k ( a ∣ s ) ( r ∑ p ( r ∣ s , a ) r + γ s ′ ∑ p ( s ′ ∣ s , a ) v π k ( j ) ( s ′ ) ) , s ∈ S 当 j → ∞ j \rightarrow \infin j → ∞ j j j ∣ ∣ v π k ( j + 1 ) − v π k ( j ) ∣ ∣ ||v_{\pi_k}^{(j+1)}-v_{\pi_k}^{(j)}|| ∣∣ v π k ( j + 1 ) − v π k ( j ) ∣∣
计算出 state value 后,就可以根据其值对策略进行优化:
π k + 1 = arg max π ( r π + γ P π v π k ) π k + 1 ( s ) = arg max π ∑ a π ( a ∣ s ) ( ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π k ( s ′ ) ) ⏟ q π k ( s , a ) , s ∈ S \pi_{k+1} = \arg\max_{\pi} (r_\pi + \gamma P_\pi v_{\pi_k})
\\
\pi_{k+1}(s) = \arg\max_{\pi} \sum_a \pi(a|s) \underbrace{\left( \sum_r p(r|s, a)r + \gamma \sum_{s'} p(s'|s, a)v_{\pi_k}(s') \right)}_{q_{\pi_k}(s, a)}, \quad s \in \mathcal{S} π k + 1 = arg π max ( r π + γ P π v π k ) π k + 1 ( s ) = arg π max a ∑ π ( a ∣ s ) q π k ( s , a ) ( r ∑ p ( r ∣ s , a ) r + γ s ′ ∑ p ( s ′ ∣ s , a ) v π k ( s ′ ) ) , s ∈ S 要想获得最优的策略,需要让 action 的奖励最大,也就是对应的 q q q
a k ∗ ( s ) = arg max a q π k ( a , s ) a_k^*(s)=\arg \max_aq_{\pi_k}(a,s) a k ∗ ( s ) = arg a max q π k ( a , s ) 对应的策略为:
π k + 1 ( a ∣ s ) = { 1 a = a k ∗ ( s ) 0 a ≠ a k ∗ ( s ) \pi_{k+1}(a|s) = \begin{cases} 1 & a = a_k^*(s) \\ 0 & a \neq a_k^*(s) \end{cases} π k + 1 ( a ∣ s ) = { 1 0 a = a k ∗ ( s ) a = a k ∗ ( s ) 整个算法的流程如下所示:
π 0 → P E v π 0 → P I π 1 → P E v π 1 → P I π 2 → P E v π 2 → P I … \pi_0 \xrightarrow{PE} v_{\pi_0} \xrightarrow{PI} \pi_1 \xrightarrow{PE} v_{\pi_1} \xrightarrow{PI} \pi_2 \xrightarrow{PE} v_{\pi_2} \xrightarrow{PI} \dots π 0 P E v π 0 P I π 1 P E v π 1 P I π 2 P E v π 2 P I … 在这里,我们有四个问题:
Q1:在 PE 阶段,如何通过贝尔曼公式计算 state value v π k v_{\pi_k} v π k
Ans:
实际上我们就是要解决这个方程:
v π k = r π k + γ P π k v π k v_{\pi_k} = r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k} v π k = r π k + γ P π k v π k 有两种方法,实际上我们在之前的课程中都学习过:
Closed-form solution:v π k = ( I − γ P π k ) − 1 r π k v_{\pi_k} = (I - \gamma P_{\pi_k})^{-1} r_{\pi_k} v π k = ( I − γ P π k ) − 1 r π k
Iterative solution:v π k ( j + 1 ) = r π k + γ P π k v π k ( j ) , j = 0 , 1 , 2 , … v_{\pi_k}^{(j+1)} = r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k}^{(j)}, \quad j = 0, 1, 2, \dots v π k ( j + 1 ) = r π k + γ P π k v π k ( j ) , j = 0 , 1 , 2 , …
Q2:在 PI 阶段,为什么新策略 π k + 1 \pi_{k+1} π k + 1 π k \pi_k π k
Ans:
证明如下:
Q3:为什么这样的一个算法可以最终到达最优策略?
Ans:
首先,我们知道:v π 0 ≤ v π 1 ≤ v π 2 ≤ ⋯ ≤ v π k ≤ ⋯ ≤ v ∗ v_{\pi_0} \leq v_{\pi_1} \leq v_{\pi_2} \leq \dots \leq v_{\pi_k} \leq \dots \leq v^* v π 0 ≤ v π 1 ≤ v π 2 ≤ ⋯ ≤ v π k ≤ ⋯ ≤ v ∗
证明如下:
Q4:policy iteration 和 value iteration 有什么关系?
Ans:
它们两者其实是一个更普遍的算法 truncated policy iteration 的两个极端。
算法如下:
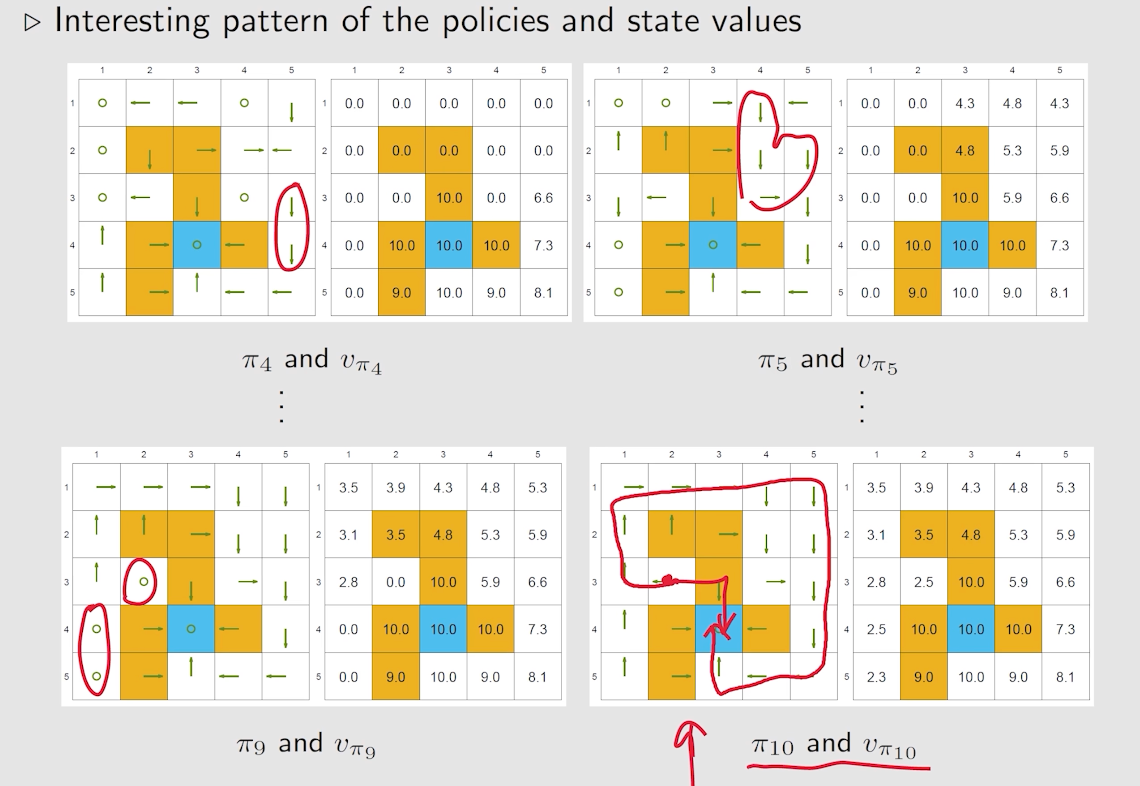
我们可以发现一个现象:靠近目标区域的策略会先达到最优。
我们首先对上面讲过的两种迭代方式进行一个对比:
Policy iteration:π 0 → P E v π 0 → P I π 1 → P E v π 1 → P I π 2 → P E v π 2 → P I … \pi_0 \xrightarrow{PE} v_{\pi_0} \xrightarrow{PI} \pi_1 \xrightarrow{PE} v_{\pi_1} \xrightarrow{PI} \pi_2 \xrightarrow{PE} v_{\pi_2} \xrightarrow{PI} \dots π 0 P E v π 0 P I π 1 P E v π 1 P I π 2 P E v π 2 P I …
Value iteration:v 0 → P U π 1 ′ → V U v 1 → P U π 2 ′ → V U v 2 → P U … v_0 \xrightarrow{PU} \pi_1' \xrightarrow{VU} v_1 \xrightarrow{PU} \pi_2' \xrightarrow{VU} v_2 \xrightarrow{PU} \dots v 0 P U π 1 ′ V U v 1 P U π 2 ′ V U v 2 P U …
具体对比如下:
Policy iteration algorithm Value iteration algorithm Comments 1) Policy: π 0 \pi_0 π 0 N/A 2) Value: v π 0 = r π 0 + γ P π 0 v π 0 v_{\pi_0} = r_{\pi_0} + \gamma P_{\pi_0} v_{\pi_0} v π 0 = r π 0 + γ P π 0 v π 0 v 0 : = v π 0 v_0 := v_{\pi_0} v 0 := v π 0 3) Policy: π 1 = arg max π ( r π + γ P π v π 0 ) \pi_1 = \arg\max_{\pi} (r_{\pi} + \gamma P_{\pi} v_{\pi_0}) π 1 = arg max π ( r π + γ P π v π 0 ) π 1 = arg max π ( r π + γ P π v 0 ) \pi_1 = \arg\max_{\pi} (r_{\pi} + \gamma P_{\pi} v_0) π 1 = arg max π ( r π + γ P π v 0 ) The two policies are the same 4) Value: v π 1 = r π 1 + γ P π 1 v π 1 v_{\pi_1} = r_{\pi_1} + \gamma P_{\pi_1} v_{\pi_1} v π 1 = r π 1 + γ P π 1 v π 1 v 1 = r π 1 + γ P π 1 v 0 v_1 = r_{\pi_1} + \gamma P_{\pi_1} v_0 v 1 = r π 1 + γ P π 1 v 0 v π 1 ≥ v 1 v_{\pi_1} \ge v_1 v π 1 ≥ v 1 v π 1 ≥ v π 0 v_{\pi_1} \ge v_{\pi_0} v π 1 ≥ v π 0 5) Policy: π 2 = arg max π ( r π + γ P π v π 1 ) \pi_2 = \arg\max_{\pi} (r_{\pi} + \gamma P_{\pi} v_{\pi_1}) π 2 = arg max π ( r π + γ P π v π 1 ) π 2 ′ = arg max π ( r π + γ P π v 1 ) \pi_2' = \arg\max_{\pi} (r_{\pi} + \gamma P_{\pi} v_1) π 2 ′ = arg max π ( r π + γ P π v 1 ) ⋮ \vdots ⋮ ⋮ \vdots ⋮ ⋮ \vdots ⋮ ⋮ \vdots ⋮
我们考虑 4)Value 这一步,也就是解决 v π 1 = r π 1 + γ P π 1 v π 1 v_{\pi_1} = r_{\pi_1} + \gamma P_{\pi_1} v_{\pi_1} v π 1 = r π 1 + γ P π 1 v π 1
v π 1 ( 0 ) = v 0 value iteration ← v 1 ← v π 1 ( 1 ) = r π 1 + γ P π 1 v π 1 ( 0 ) v π 1 ( 2 ) = r π 1 + γ P π 1 v π 1 ( 1 ) ⋮ → truncated policy iteration ← v ˉ 1 ← v π 1 ( j ) = r π 1 + γ P π 1 v π 1 ( j − 1 ) ⋮ → policy iteration ← v π 1 ← v π 1 ( ∞ ) = r π 1 + γ P π 1 v π 1 ( ∞ ) \begin{align*}
& \color{red}{v_{\pi_1}^{(0)}} = v_0 \\
\text{value iteration} \leftarrow \color{red}{v_1} \leftarrow \quad & v_{\pi_1}^{(1)} = r_{\pi_1} + \gamma P_{\pi_1} v_{\pi_1}^{(0)} \\
& v_{\pi_1}^{(2)} = r_{\pi_1} + \gamma P_{\pi_1} v_{\pi_1}^{(1)} \\
& \vdots \\
\color{red}{\rightarrow \text{truncated policy iteration}} \leftarrow \color{red}{\bar{v}_1} \leftarrow \quad & v_{\pi_1}^{(j)} = r_{\pi_1} + \gamma P_{\pi_1} v_{\pi_1}^{(j-1)} \\
& \vdots \\
\rightarrow \text{policy iteration} \leftarrow \color{red}{v_{\pi_1}} \leftarrow \quad & v_{\pi_1}^{(\infty)} = r_{\pi_1} + \gamma P_{\pi_1} v_{\pi_1}^{(\infty)}
\end{align*} value iteration ← v 1 ← → truncated policy iteration ← v ˉ 1 ← → policy iteration ← v π 1 ← v π 1 ( 0 ) = v 0 v π 1 ( 1 ) = r π 1 + γ P π 1 v π 1 ( 0 ) v π 1 ( 2 ) = r π 1 + γ P π 1 v π 1 ( 1 ) ⋮ v π 1 ( j ) = r π 1 + γ P π 1 v π 1 ( j − 1 ) ⋮ v π 1 ( ∞ ) = r π 1 + γ P π 1 v π 1 ( ∞ ) 中间的 truncated policy iteration 是一般情况。value iteration 和 policy iteration 可看作是 truncated policy iteration 在 j = 1 j=1 j = 1 j → ∞ j \rightarrow \infin j → ∞
其伪代码如下所示:
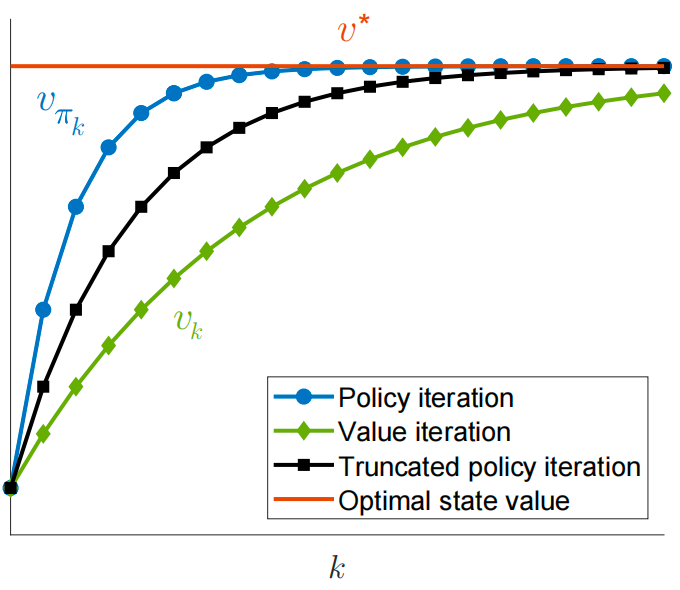
这三种算法的性能如下: