操作系统
Lec6: 进程同步
临界区问题、Peterson 解、硬件原子指令、互斥锁、信号量、管程,以及经典同步问题(生产者-消费者/读者-写者/哲学家就餐)。
进程同步
目标
- 引入临界区问题,它的解决方案可以用于确保共享数据的一致性。
- 讨论临界区问题的软件与硬件解决方案。
- 分析进程同步的多个经典问题。
- 探讨解决进程同步问题的多个工具。
背景
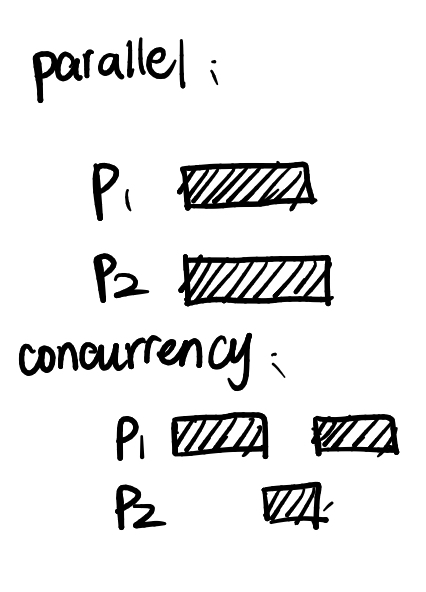
首先我们来弄清两个概念:并行(Parallel)、并发(Concurrency)。具体如下图所示:
并行或者并发有可能会影响到进程数据的完整性。以之前的 consumer-and-producer 的问题为例子,生产者消费者对应程序如下:
// producer
while (true) {Produce an item;
buffer[in] = item;
while (((in + 1) % BUFFER_SIZE == out)
; /* do nothing -- no free buffers */
//buffer[in] = item; /* move the line before while */
count++;
in = (in + 1) % BUFFER_SIZE;
}
// consumer
while (true) {
while (in == out)
; //do nothing, nothing to consume
Remove an item from the buffer;
item = buffer[out];
count--;
out = (out + 1) % BUFFER SIZE;
return item;
} 分别将其转化为机器语言如下:
register1 = counter
register1 = register1 + 1
counter = register1 register2 = counter
register2 = register2 - 1
counter = register2 实际运行的时候,因为指令乱序和其他原因,可能会出现下面的情况:

导致 counter 计算错误。
race condition
像上面这种多个进程并发访问和操作统一数据并且执行结果和特定访问顺序有关,称为 race condition(竞争条件)。为了防止竞争条件,需要确保一次只有一个进程可以操作变量 counter。为了做出这种保证,要求进程按照一定的方式来同步。
实际上,想产生 race condition,有以下条件:
- 多个进程
- 进程之间共享内存
- 至少有一个进程有写操作
临界区问题
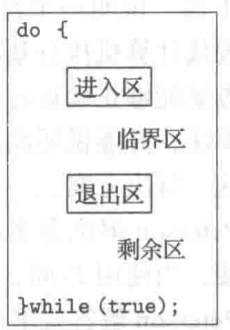
首先我们来介绍下什么是临界区(critical section)。假设某个系统有 n 个进程,每个进程都有一段代码,称为临界区(critical section)。进程在执行该区时可能修改公共变量、更新一个表、写一个文件等。
该系统的重要特征是,当一个进程在临界区内执行时,其他进程不允许在它们的临界区内执行。也就是说,没有两个进程可以在它们的临界区内同时执行。
在进入临界区前,每个进程应请求许可。实现这一请求的代码区段称为进入区(entry section)。临界区之后可以有退出区(exit section),其他代码为剩余区(remainder section)。
临界区问题的解决方案应满足如下三条要求:
- 互斥(mutual exclusion):如果进程在其临界区内执行,那么其他进程都不能在其临界区内执行。
- 进步(progress):如果没有进程在其临界区内执行,并且有进程需要进入临界区,那么只有那些不在剩余区内执行的进程可以参加选择,以便确定谁能下次进入临界区,而且这种选择不能无限推迟。(没有 starvation)
- 有限等待(bounded waiting):从一个进程做出进入临界区的请求直到这个请求允许为止,其他进程允许进入其临界区的次数具有上限。(没有 starvation)
对于一个临界区,我们可以将其分为多个临界区,只要这些临界区互不影响(操作的共享内存不一样)。
有两种常用的方法,用于处理操作系统的临界区问题:抢占式内核(preemptive kernel)与非抢占式内核(nonpreemptive kernel)。这两种和我们在调度这一节中学的差不多,这里就不多解释了。
Peterson 解决方案
下面,说明一个经典的基于软件的临界区问题的解决方案,称为Peterson解决方案。
Peterson 解决方案适用于两个进程交错执行临界区与剩余区。两个进程为和。为了方便,当使用时,用来表示另一个进程,即。
Peterson 解答要求两个进程共享两个数据项:
int turn;boolean flag[2];
变量turn表示哪个进程可以进人临界区。即如果turn==i,那么进程允许在临界区内执行。数组flag表示哪个进程准备进人临界区。例如,如果flag[i]为true,那么进程准备进人临界区。
具体算法如下:
// 进程 P_i 的代码
do{
flag[i] = true;
turn = j;
while (flag[j] $$ turn == j);
// 临界区
// ······
flag[i] = false;
// 剩余区
}whie(true);- 互斥:
turn只有一个值,每次最多只有一个进程可以进去。 - 进步:
turn一定会有一个值,保证了一定会有进程进来 - 有限等待:一个进程在临界区里执行完后,其flag 被置为 false,此时就会让另一个进程进入临界区。
然而,这个算法却有一点小问题。我们在之前的课程中学习到,现代计算机的硬件架构通常支持指令的乱序,也就是说,可能会出现下面的情况:
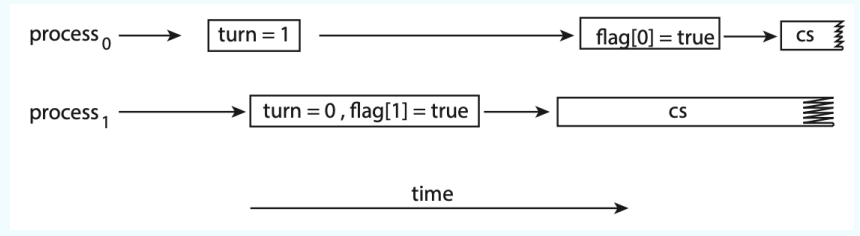
因为 turn 和 flag 的赋值是相互独立的(没有WAW, RAW, WAR这三种情况),因此,硬件很可能会将这两个赋值的顺序进行调换。这是,turn 的值就变得随机,导致进程的进入变得随机。
同时,由于语句while (flag[j] $$ turn == j)一直空转,导致 CPU 的大量资源都被占用。
硬件同步
我们之前对于临界区的问题的解答都是基于软件的。对于上面说到的硬件层面的问题,我们需要从硬件的角度来解答。实际上,所有这些解答都是基于加锁为前提的,即通过锁来保护临界区。
- Many systems provide hardware support for critical section code
- Uniprocessors(单处理器) – could disable interrupts
- Currently running code would execute without preemption
- 对于单处理器环境的情况,临界区问题可以很简单地解决:在修改共享变量的时候只要禁止中断出现。这样,就能够确保当前指令流可以有序执行,而且不会被抢占。
- Generally too inefficient on multiprocessor systems
- 对于多处理器这种方案是不可行的。多处理器的中断禁止很好使,因为消息要传递到所有处理器。消息传递会延迟进入临界区,并降低系统效率。
- Operating systems using this not broadly scalable
- Modern machines provide special atomic hardware instructions
- 提供特殊的原子操作
- Atomic = non-interruptable
- Either test memory word and set value
- Or swap contents of two memory words
test_and_set
这个原子操作的定义如下:
boolean TestAndSet (boolean *target)
{
boolean rv = *target;
*target = TRUE;
return rv:
}
用它来实现的锁代码如下所示:
while (true) {
while ( TestAndSet (&lock )); // do nothing
// critical section
lock = FALSE;
// remainder section
}
Swap
定义:
void Swap (boolean *a, boolean *b)
{
boolean temp = *a;
*a = *b;
*b = temp:
}
实现:
while (true) {
key = TRUE;
while ( key == TRUE)
Swap (&lock, &key );
// critical section
lock = FALSE;
// remainder section
}
Compare_and_swap
定义:
int compare_and_swap(int *value, int expected, int new_value)
{
int temp = *value;
if (*value == expected)
*value = new_value;
return temp;
}
实现:
while (true){
while (compare_and_swap(&lock, 0, 1) != 0)
; /* do nothing */
/* critical section */
lock = 0;
/* remainder section */
}
Bounded-waiting with compare-and-swap
while (true) {
waiting[i] = true;
key = 1;
while (waiting[i] && key == 1)
key = compare_and_swap(&lock,0,1);
waiting[i] = false;
/* critical section */
j = (i + 1) % n;
while ((j != i) && !waiting[j])
j = (j + 1) % n;
if (j == i)
lock = 0;
else
waiting[j] = false;
/* remainder section */
}
Mutex Locks(互斥锁)
- Previous solutions are complicated and generally inaccessible to application programmers
- OS designers build software tools to solve critical section problem
- Simplest is mutex lock
- Boolean variable indicating if lock is available or not
- 互斥锁使用一个boolean变量去标识一个所是否是可获得的(available)
- Protect a critical section by
- First acquire() a lock
- Then release() the lock
- Calls to acquire() and release() must be atomic
- Usually implemented via hardware atomic instructions such as compare-and-swap.
- But this solution requires busy waiting
- 下面代码实现的主要缺点是,它需要忙等待(busy waiting)。
- This lock is therefore called a spinlock
- 当有一个进程在临界区中,任何其他进程在进入临界区时必须连续循环调用
acquire()。这类锁也被称为自旋锁(spinlock)
具体代码如下:
while (true) {
acquire lock
critical section
release lock
remainder section
}
两个函数如下所示:
acquire() {
while (!available)
; /* busy wait */
available = false;
}
release() {
available = true;
}
不过,自旋锁却是有一个优点:当进程在等待锁的时候,没有上下文切换。这大大减少了时间成本。因此,当使用锁的时间较短的时候,自旋锁还是有用的。
自旋锁通常用于多处理器系统,一个线程可以在一个处理器上“旋转”,而其他线程在其他处理器上执行临界区。
Semaphore(信号量)
-
Synchronization tool that is less complicated
-
Semaphore S – integer variable
-
Two indivisible operations modify S:
-
对于信号量 S 来说,除了初始化之外只能通过两个标准原子操作
wait()和signal()来访问- wait() and signal()
- 实际上,我们可以认为,
wait()和signal()分别为“请求”和“释放”。前者循环等待资源,得到资源的时候将信号量减1。后者释放资源时将信号量加1。我们可以将信号量看作是剩余的资源数。 - originally called P() and V()
wait()和signal()原先被称为P和S
-
Can only be accessed via two indivisible (atomic) operationswait (S)
-
wait (S) { while (S <= 0) ; // no-op S--; } -
signal (S) { S++; } -
Can be implemented without busy waiting
Usage as General Synchronization Tool
操作系统通常区分计数信号量(Counting semaphore )和二进制信号量(Binary semaphore)
- Counting semaphore – integer value can range over an unrestricted domain
- 计数信号量通常用于控制访问具有多个实例的某种资源。信号量的值就是可用资源数量。
- Binary semaphore – integer value can range only between 0 and 1; can be simpler to implement
- Also known as mutex locks
- 事实上,可以使用二进制信号量来实现互斥。
- Can implement a counting semaphore S as a binary semaphore
- Provides mutual exclusion
Semaphore S; // initialized to 1
wait (S);
// Critical Section
signal(S); 注意,上面的例子中,Semaphore S 被设置成了1,用于表示可以进临界区的名额。
下面是使用 Semaphore 的一个例子:

上面的操作实现了两个任务的先后执行。
实际上,上面这个例子还提示了我们,信号量的初值是非常重要的。
Semaphore Implementation
想要实现 Semaphore,最简单的方法就是使用 busy waiting。
为了解决busy waiting,我们需要操作系统给我们实现两种操作:sleep(block)、wakeup,具体的思想是,当一个进程执行操作wait()并且发现信号量的值部位正的时候,他必须等待。然而,该进程不是忙等待而是阻塞自己。阻塞操作将一个进程放到和信号量相关的等待队列中,并且将这个进程状态切换成等待状态。
- With each semaphore there is an associated waiting queue. Each semaphore has two data items:
- value (of type integer)
- pointer to a linked-list of PCBs.
- Two operations (provided as basic system calls):
- block (sleep) – place the process invoking the operation on the appropriate waiting queue.
- wakeup – remove one of processes in the waiting queue and place it in the ready queue.
代码如下:


一般来说,默认semaphore是使用这种方式实现的。
Deadlock and Starvation
死锁和饥饿是两个经典的问题。
- Deadlock – two or more processes are waiting indefinitely for an event that can be caused by only one of the waiting processes

上面是死锁的一个例子。具体来说,假设Po执行wait(S),接着P执行wait(Q)。当Po执行wait(Q)时,它必须等待,直到P执行signal(Q)。类似地,当P执行wait(S)时,它必须等待,直到Po执行signal(S)。由于这两个操作signal()都不能执行,这样P。和 P就死锁了。
另一种问题是无限阻塞(indefinite blocking)或饥饿(starvation),即进程无限等待信号量。如果对与信号量相关的链表按照LIFO(后进先出)顺序来增加和删除进程,那么可能发生无限阻塞。
Classical Problems of Synchronization(经典同步问题)
主要分为以下三种:
- Bounded-Buffer Problem
- Readers and Writers Problem
- Dining-Philosophers Problem
Bounded-Buffer Problem
这个问题也叫做“生产者-消费者问题”,具体定义如下:
多个生产者和多个消费者共享一个固定大小的缓冲区,必须保证互斥访问,并且不能溢出或取空。
可以使用以下方案来解决:
- N buffers, each can hold one item
- Semaphore mutex initialized to the value 1
- Semaphore full initialized to the value 0, counting full items
- Semaphore empty initialized to the value N, counting empty items.
代码如下所示:

可以这样理解:
- 生产者检测缓冲区是否是空的,是空的话就进行生产,直到缓冲区满。
- 而消费者检测缓冲区是否满,是满的话就进行消费,直到缓冲区空。
- 为了保证没有生产者和消费者同时运行,需要一个互斥锁
mutex。
Readers-Writers Problem
- A data set is shared among a number of concurrent processes
- Readers – only read the data set; they do not perform any updates
- Writers – can both read and write.
- Problem – allow multiple readers to read at the same time. Only one single writer can access the shared data at the same time.
- Shared Data
- Data set
- Semaphore mutex initialized to 1, to ensure mutual exclusion when readcount is updated.
- Semaphore wrt initialized to 1.
- Integer readcount initialized to 0.
具体来说,就是分为两种成员:reader 和 writer。其中,reader 只能读,但 writer 可读可写。
对于这个问题的解答,可以定义以下数据结构进行同步:
semaphore rw_mutex = 1;
semaphore mutex = 1;
int read_count = 0; 两个进程的代码如下所示:

对于 reader 进程,因为 reader 不仅要和 writer 互斥,reader 之间也需要互斥,所以可以看到代码中为read_count变量添加了互斥锁mutex。
Dining-Philosophers Problem(哲学家就餐问题)
假设有5个哲学家,他们的生活只是思考和吃饭。这些哲学家共用一个圆桌,每位都有一把椅子。在桌子中央有一碗米饭,在桌子上放着5根筷子。当一位哲学家思考时,他与其他同事不交流。时而,他会感到饥饿,并试图拿起与他相近的两根筷子(筷子在他和他的左或右邻居之间)。一个哲学家一次只能拿起一根筷子。显然,他不能从其他哲学家手里拿走筷子。当一个饥饿的哲学家同时拥有两根筷子时,他就能吃。在吃完后,他会放下两根筷子,并开始思考。 哲学家就餐问题(dining-philosophers problem)是一个经典的同步问题,因为它是大量并发控制问题的一个例子。这个代表型的例子满足:在多个进程之间分配多个资源,而且不会出现死锁和饥饿。
- Shared data
- Bowl of rice (data set)
- Semaphore chopstick [5] initialized to 1
- 对于哲学家就餐问题,有两个共享数据:
- 饭,就是数据集合
- 5 支筷子,就是锁
一种简单的解决方法是每只筷子都用一个信号量表示,哲学家可以通过wait()获得筷子,也可以通过signal()释放相应的筷子,也就是:
semaphore chopsticks[5] 对应算法如下:

这里我们假定一下事实:
- 对于编号为i(i=0~4)的哲学家,其左边的筷子编号为i,右边的筷子编号为((i+1)%5)
- 哲学家只有拿到两双筷子才可以吃饭
考虑这样的一种情况:所有哲学家同时拿起左边的筷子,此时,5支筷子全部上锁,因此没有哲学家可以拿起右手的筷子,导致死锁。
死锁问题有多种解决措施:
-
允许最多4个哲学家同时坐在桌子上,避免所有筷子同时消失的情况
Semaphore semaphore = 4
-
只有一个哲学家的两根筷子都可以使用的时候,他才可以拿起它们(必须在临界区内拿起两根筷子)

-
使用非对称的解决方案:单数的哲学家先拿左边的筷子,双数的哲学家先拿右边的筷子

但是,没有死锁的解决方案不一定能消除饥饿。
Monitor
不讲
Pthreads Synchronization
- Pthreads API is OS-independent
- It provides:
- mutex locks
- condition variables
- Non-portable extensions include:
- read-write locks
- spin locks
以下是 Pthreads 的几个常见的函数:
pthread_mutex_init(&mutex, NULL):初始化函数pthread_mutex_lock(&mutex):上锁函数pthread_mutex_unlock(&mutex):解锁函数
对于上面的这些函数,在操作正确的时候,返回的值是 0。


Written by
ZZC
每天研究怎么摸鱼的神人
Comments
评论功能即将上线