论文阅读
Imitating Animals: 从动物模仿到真实四足敏捷运动
RSS 2020 论文,DeepMimic 的真机续作:把动作捕捉先验从仿真特技搬到真实 Laikago 四足上,核心解决域差距与硬件磨损下的部署问题。
论文概述
这是 DeepMimic 的续作,这次是 "Imitating Animals"(模仿真狗)。
上一篇论文是在完美的模拟环境里做特技,这一篇论文的核心挑战变成了:如何把这些动作部署到真实的、充满摩擦和误差的物理机器人(Laikago 机器狗)上。
可以把这篇论文看作是 “DeepMimic 2.0:从模拟走向现实”。
| 维度 | 上一篇 DeepMimic | 这一篇 Imitating Animals |
|---|---|---|
| 主要舞台 | 计算机屏幕(虚拟世界) | 物理世界(真实机器人) |
| 核心挑战 | 怎么让动作像真的? | 怎么让动作在真机上不摔倒? |
| 数据来源 | 人类动作捕捉 | 真狗动作捕捉 9 |
| 新增技术 | RSI, ET | Domain Adaptation (领域自适应) |
解决问题
当前(写论文的时候)的工作有以下困境:
- 手动写代码太难了: 大量工作致力于为各种运动技能设计控制策略。然而,设计控制策略通常涉及漫长的开发过程,并且需要对底层系统和所需技能有相当多的专业知识。 传统的机器人控制(Manual design)需要工程师极度了解物理学和电机原理。想让机器人做个后空翻,工程师可能要算好几个月的公式 。
- 纯强化学习(RL)太怪了: 虽然 RL 可以自动学习,但如果没有参考动作(Reference Motion),机器人学会的动作往往非常不自然(Unnatural behaviors),甚至可能因为动作太猛把机器人的电机烧坏,在现实中根本没法用 。
- 现实世界太残酷了(核心痛点): 上一篇 DeepMimic 在模拟器里很成功,但模拟器(Sim)和现实(Real)是有差距的(比如摩擦力、电机延迟、地面硬度)。直接把模拟器里练好的脑子拷贝到真机器狗身上,它通常会立刻摔倒。这就是著名的 "Sim-to-Real Gap" 。
针对这些问题,这篇论文提出了一套完整的模仿学习系统 (Imitation Learning System) ,目标如下:
- 利用真狗的数据: 直接用真狗的动作数据(Mocap)作为“教科书”,让机器人模仿。这样就不需要设计复杂的奖励函数,动作也会很自然、优雅 。
- 解决现实迁移问题: 提出了一种“样本高效的领域自适应技术” (Sample Efficient Domain Adaptation) 。这是本文最大的技术贡献,让机器狗能在模拟器里练好,然后快速适应现实世界的物理环境。
核心流程
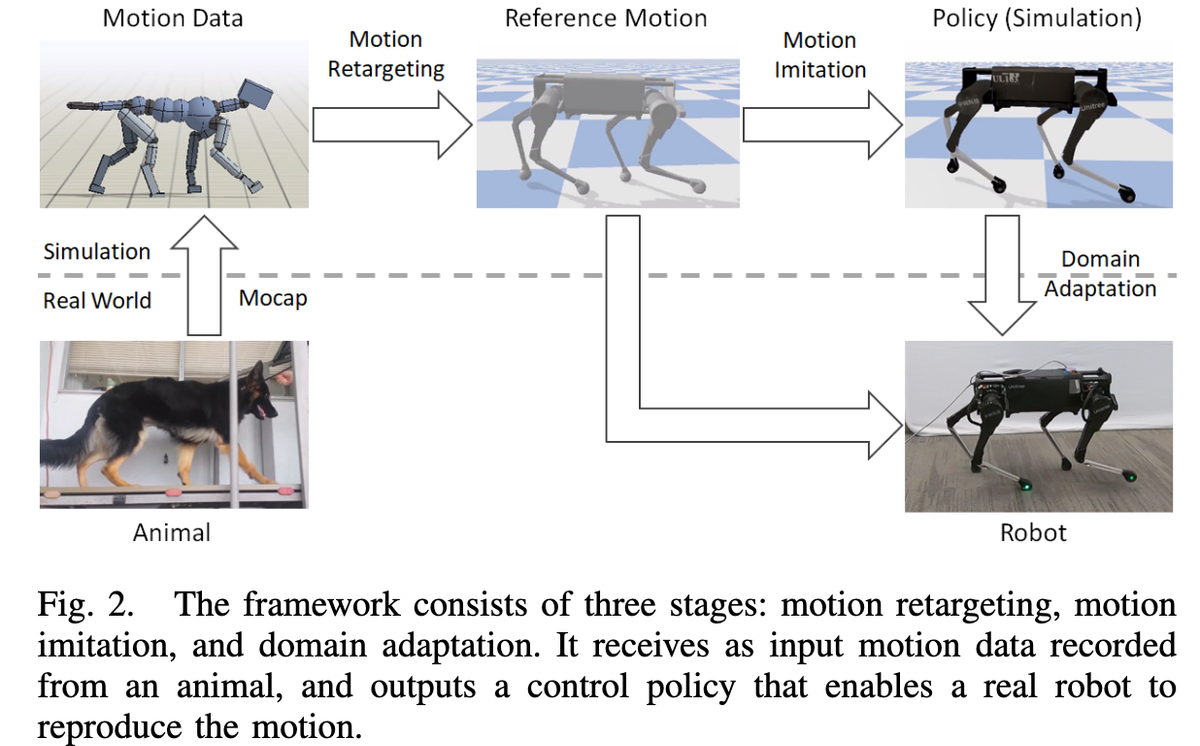
整篇文章的流程如下:
- Motion Retargeting (动作重定向): 把真狗的骨架映射到机器狗上。
- Motion Imitation (动作模仿): 在模拟器里训练(这就是 DeepMimic 的部分)。
- Domain Adaptation (领域自适应): 把策略迁移到真机。
Motion Retargeting (动作重定向)
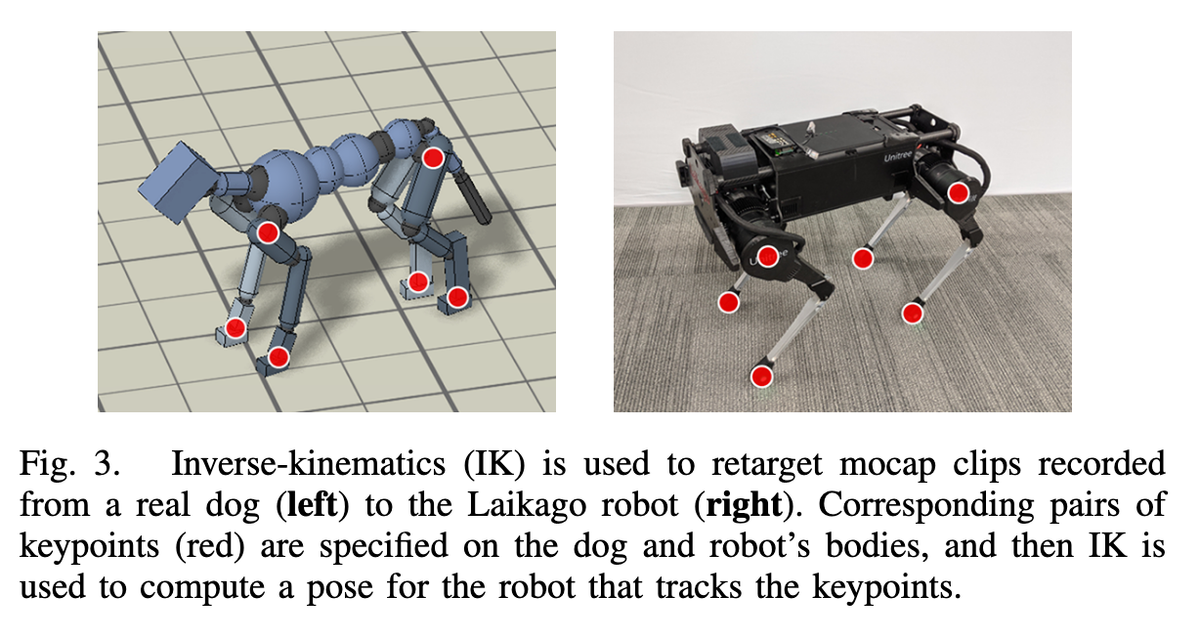
- 问题:主体的形态(Morphology)往往与机器人的形态不同。
- 真狗的腿可能长 30cm,膝盖向前弯;机器狗的腿可能长 20cm,膝盖向后弯。直接把真狗的关节角度复制给机器人,机器人可能会把腿折断或者脚根本碰不到地。
- 方法:源动作通过逆运动学 (Inverse-Kinematics, IK) 被重定向到机器人的形态上。
- 不直接复制关节角度(Forward Kinematics),而是复制“脚的位置”。
- 逆运动学 (IK): 这是一种数学反推方法。已知“脚要在坐标 (x, y, z) 落地”,IK 可以算出“为了让脚踩到那里,大腿和小腿分别需要转多少度”。
- 建立映射:在主体(动物)身体上指定一组源关键点,这些关键点与机器人身体上的对应目标关键点配对。
- 告诉计算机,狗的“左前爪”对应机器人的“左前足端”,狗的“屁股”对应机器人的“后部机身”。
- 关键点:如上图所示,关键点包括脚和臀部的位置。
- 为什么选这些点? 脚决定了接触点(走得稳不稳),臀部决定了身体的整体位移(走得快不快)。只要这两个部位对齐了,动作大概率就“像”了。
下面对公式进行说明:
- 变量解释:
- :在每个时间步,源动作指定每个关键点 的 3D 位置
- 这是真狗动作捕捉数据提供的目标坐标(比如:第 1 秒时,左脚应该在坐标 [10, 0, 5])。
- :对应的目标关键点 由机器人的姿态 决定,该姿态以广义坐标表示。
- 是机器人当前的关节角度。这句话的意思是:机器人的脚在哪里,取决于它的关节怎么转。
- :在每个时间步,源动作指定每个关键点 的 3D 位置
- 优化目标:我们要找到一组机器人的关节角度 ,使得这个公式的值最小。
- :意思是真狗的脚位置 () 和机器人的脚位置 () 距离越近越好。
- :包含一个额外的正则化项,以鼓励姿态保持与默认姿态 相似,并且 是一个指定每个关节正则化系数的对角矩阵。
- 为什么需要这一项? IK 算出的解可能很怪异(比如为了让脚碰到地,膝盖扭曲了 360 度)。
- 作用: 强迫机器人在尽量满足脚的位置的同时,身体姿势要尽量接近“自然站立姿态” (),不要扭成麻花。 是权重,决定了如果你扭曲某个关节,惩罚会有多重。
Motion Imitation (动作模仿)
强化学习基础定义 (RL Formulation)
将动作模仿表述为一个强化学习问题。在强化学习中,目标是学习一个控制策略,使智能体能够在给定任务中最大化其期望回报 。
在每个时间步 ,智能体从环境中观察状态 ,并根据其策略 采样一个动作 。然后智能体执行该动作,导致转移到新状态 并获得一个标量奖励 。
和 DeepMimic 一样,目标是最大化长期累积奖励。
策略的输入与输出 (Policy Inputs & Outputs)
采用 DeepMimic 中类似的动作模仿方法。策略的输入增加了一个额外的目标 ,指定机器人应该模仿的动作。
- 策略:
- 将给定的状态 和目标 映射为动作分布
- 在每个时间步以 30Hz 的频率被查询以获取新动作
- 输入:
- 状态 ,由机器人过去三个时间步的姿态 和过去三个动作 表示。
- 不再只输入“当前帧”,而是输入“过去三帧”。
- 在真实世界中,传感器有延迟,且单纯的一帧数据无法准确反映速度和加速度。输入历史信息可以让神经网络隐式地推断出速度和系统的延迟特性。
- 姿态特征
- 由根节点方向(横滚、俯仰、偏航)的 IMU 读数和每个关节的局部旋转组成。 姿态特征中不包含根节点位置,以避免在现实世界部署期间需要估计根节点位置。
- 在模拟器里,上帝视角知道机器人精确位置。但在现实里,机器人不知道自己在世界地图的哪个坐标(除非有昂贵的GPS或动捕系统)。为了让策略能独立运行,作者强迫它只依赖随身携带的传感器(IMU + 关节编码器)。
- 目标 指定了参考动作在未来四个时间步的目标姿态,跨度约为 1 秒。
- 状态 ,由机器人过去三个时间步的姿态 和过去三个动作 表示。
- 输出:动作 ,指定了每个关节 PD 控制器的目标旋转角度。
- 为了确保动作更平滑,PD 目标在应用到机器人之前首先经过低通滤波器处理。
- 低通滤波: 这是为了保护电机。神经网络输出的信号可能会剧烈抖动,直接发给电机可能会导致过热或损坏,滤波让指令变柔和。
奖励函数 (Reward Function)
奖励函数鼓励策略在每个时间步跟踪参考动作的目标姿态序列 ,其结构和 DeepMimic 几乎一样,也是加权求和。具体公式如下:
各个子奖励项定义如下:
| 符号 | 含义 | 权重 (w) | 解读 |
|---|---|---|---|
| 姿态 (Pose) | 0.5 | 最重要。半壁江山都是看关节角度像不像 | |
| 末端 (End-effector) | 0.2 | 脚的位置。权重第二大,保证走得稳 | |
| 根节点姿态 (Root Pose) | 0.15 | 身体整体的朝向和位置 | |
| 根节点速度 (Root Vel) | 0.1 | 身体跑得快不快 | |
| 关节速度 (Velocity) | 0.05 | 最不重要。只要动作像就行,动作快慢有一点误差没关系 |
- 姿态奖励 (Pose Reward) :
- vs : 比较真狗 () 和机器狗 () 每个关节旋转角度的差异。
- 系数 -5: 中等严厉。允许一点点误差,但不能差太多。
- 速度奖励 (Velocity Reward) :
- 比较关节角速度(转得有多快)。
- 系数 -0.1: 非常宽容。
- 为什么? 速度信号通常充满噪声(抖动)。如果对速度惩罚太狠(比如用 -5),机器狗为了匹配速度可能会发生高频震荡,导致电机过热。所以这里作者选择“睁一只眼闭一只眼”。
- 末端执行器奖励 (End-effector Reward):
- 含义: 比较四只脚(末端)相对于身体的 3D 位置。
- 系数 -40: 极其严厉!
- 为什么? 脚的位置决定了接触点。如果真狗的脚落地了,而机器狗的脚偏了 2 厘米导致悬空,整个物理状态就会完全不同(从走路变成摔倒)。所以这一项必须精准,容不得沙子。
- 根节点姿态奖励 (Root Pose Reward):
- 含义: 包含两部分:
- 位置误差 (): 系数 -20。要求机器狗必须跟上真狗的移动轨迹。
- 旋转误差 (): 系数 -10。要求机器狗的身体朝向(比如头朝北)必须正确。
- 含义: 包含两部分:
Domain Adaptation (领域自适应)
由于模拟环境与现实世界的动力学之间存在差异,在模拟中训练出来的策略,当部署到物理系统(真机)上时,往往表现不佳。
这篇论文提出了一种样本高效 (sample efficient) 的适应技术,用于将策略从模拟环境迁移到现实世界。
Domain Randomization
Domain randomization is a simple strategy for improving a policy's robustness to dynamics variations
翻译: 领域随机化是一种简单的策略,用于提高策略对动力学变化的鲁棒性 (Robustness)。
我们需要在训练期间改变动力学参数,从而鼓励策略学习在不同动力学条件下都能起作用的策略。
然而,可能还是会有一些局限性:
- 可能没有任何一种单一策略能在所有环境中都有效
- 由于现实世界中存在未建模的效应 (unmodeled effects),那些对不同模拟动力学具有鲁棒性的策略在部署到物理系统时仍可能失败。
Domain Adaptation (领域自适应)
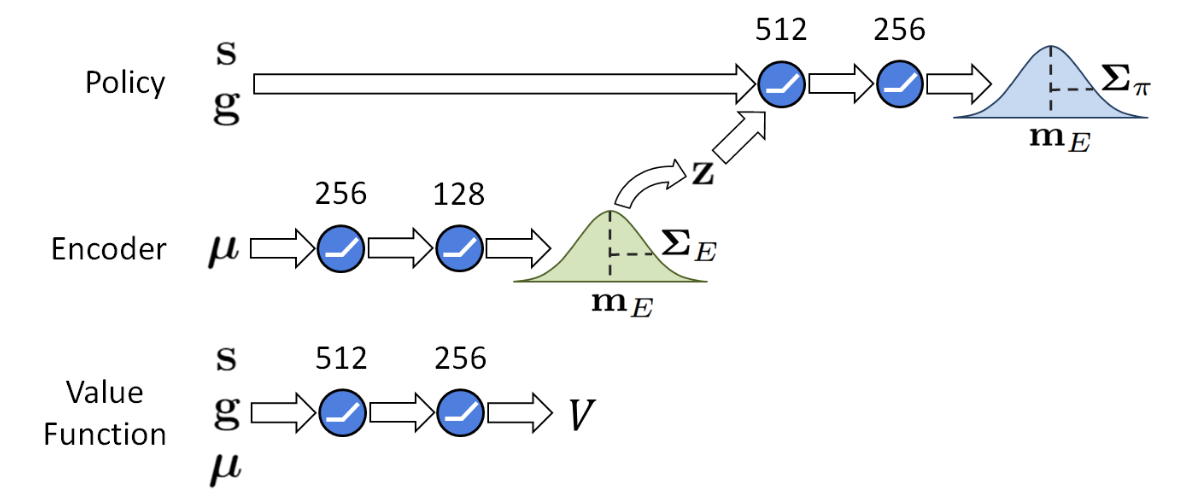
- 新增输入:
- :代表在模拟训练期间被随机化的动力学参数的值,其包含了摩擦力、质量、电机强度等物理量。
- 例如
- :代表在模拟训练期间被随机化的动力学参数的值,其包含了摩擦力、质量、电机强度等物理量。
- 过程:
- 采样:在每个回合开始时,根据分布 采样一组随机参数。
- 编码:然后,动力学参数通过一个随机编码器 (Encoder) 被编码为一个隐嵌入 (Latent Embedding) ,并且 作为额外的输入提供给策略 。
- :这是一个神经网络。输入物理参数 ,输出一个分布(通常是高斯分布),然后从中采样出 。
- :策略网络(大脑)。它现在的决策不仅取决于它看到了什么 (),还取决于它“感觉”到了什么 ()。
- 问题:
- 策略学到的战略可能会依赖于 必须是对系统真实动力学的精确表示。
- 过拟合:这可能导致脆弱的行为,即策略针对给定的 所采用的战略可能会过拟合到对应参数 的精确动力学上。
于是,提出了

Written by
ZZC
每天研究怎么摸鱼的神人
Comments
评论功能即将上线