论文阅读
AMP: 对抗动作先验替代复杂奖励函数
IROS 2022 论文 AMP:用判别器学习'是否像参考动作'的对抗信号,替代工程师手写的复杂奖励函数,让四足以自然步态学会运动。
核心痛点
- 人工调参太累: 以前要让机器狗跑得好,工程师要写几十行复杂的奖励函数(惩罚抖动、奖励抬腿高度、惩罚能耗...),稍微调错一点,狗就抽搐。
- 动作不自然: 如果只奖励“向前跑”,机器狗可能会学会一种极其怪异、高能耗的震动步态(Jittery behaviors),根本没法在真机上用。
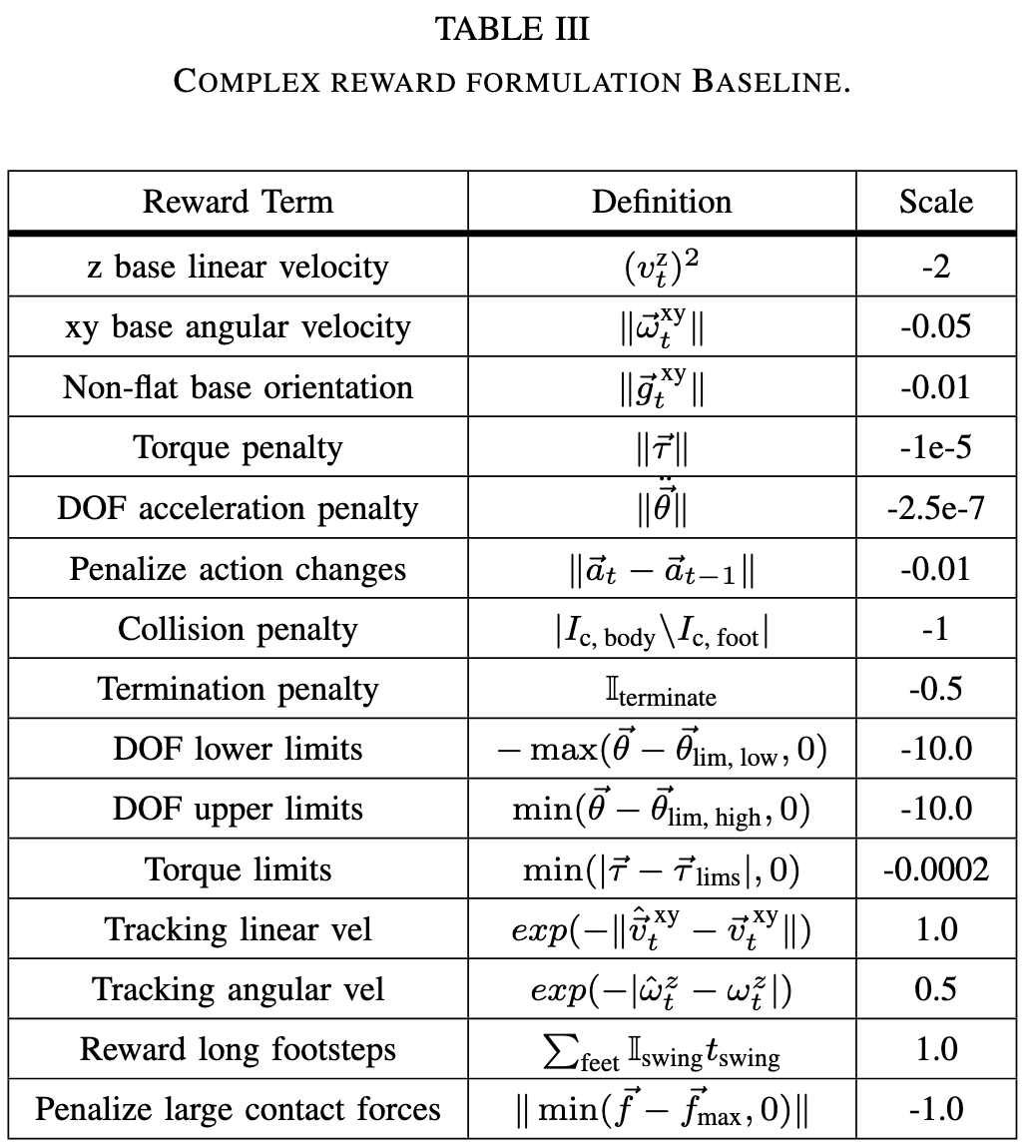
核心解法
作者引入了 AMP 技术,把奖励函数拆成了两部分:
- 任务奖励 (, Task Reward): 非常简单,只包含两项:“速度跟上了吗?” 和 “方向对了吗?”。
-
- 输入变量:
- 和 : 指令速度(比如你让它跑 1m/s)。
- 和 : 实际速度(机器狗当前真的跑了多快)。
- 输入变量:
-
- 判别器目标函数 (Discriminator Objective)
- 这是为了训练裁判,让它火眼金睛。
- 直观解释 (Least Squares GAN):
- 对于真狗数据 (Real),希望 的输出尽可能接近。
- 对于机器狗数据 (Fake),希望 的输出尽可能接近 -1。
- 操作: 这是一个最小二乘法损失函数。判别器通过最小化这个误差来不断进化。
- 风格奖励 (, Style Reward) —— 本文重点:
- 不再人工写公式,而是训练一个判别器 (Discriminator)。
- 判别器的工作: 它看过真狗的动作数据(Reference Motion)。当你控制的机器狗做动作时,判别器会打分:“这动作像真狗吗?”像就给高分,不像就给低分。
- 数据来源: 仅仅 4.5秒 的一只德国牧羊犬的动作捕捉数据(走路、小跑、慢跑)。
-
- 输入变量: ,即判别器对当前动作的打分。
- 操作:
- 回顾上面,判别器认为“真”的动作会输出。
- 如果 (动作很完美),那么 ,奖励 (满分)。
- 如果 (动作很假),那么 ,奖励 (零分)。
- 输出: 一个 [0, 1] 之间的标量。越像真狗,分数越高。
- 总奖励:
- 论文中提到权重设置为:风格奖励 ,任务奖励 。
- 说明“动作自然”是第一位的
训练过程
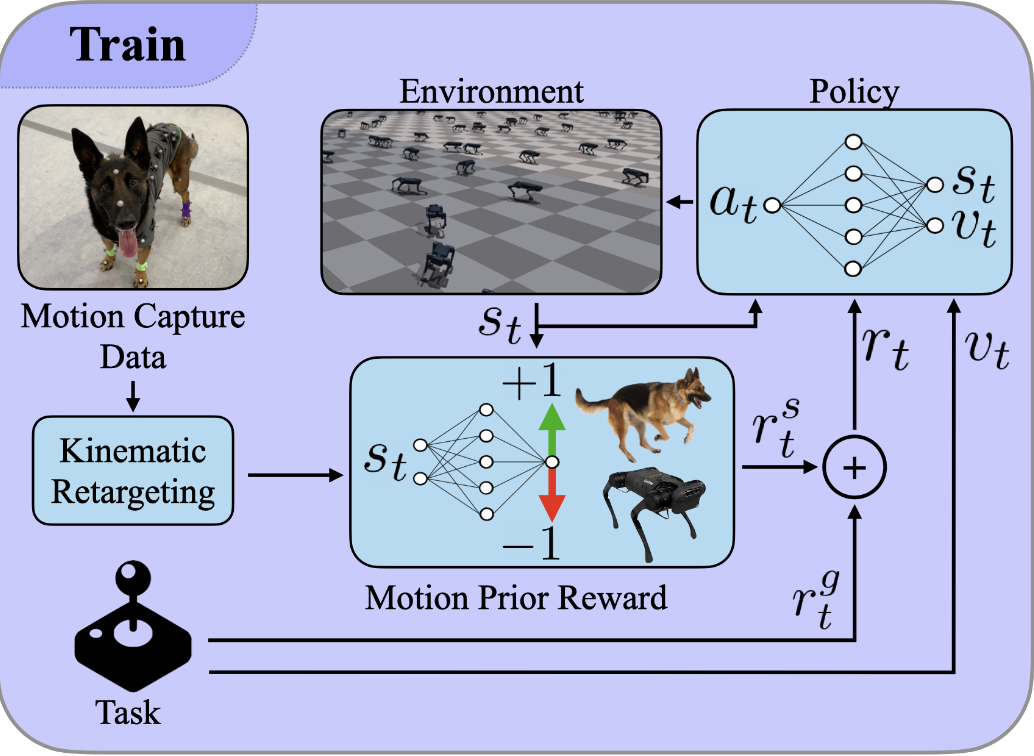
这张图展示了 AMP 系统是如何像教学生一样训练机器狗的。我们可以把它分为三个部分来看:
- 左侧:老师的教材 (Reference Data)
- Motion Capture Data: 也就是那 4.5 秒的德国牧羊犬视频数据。
- Kinematic Retargeting: 把真狗的骨架数据映射转换成机器狗的关节数据,作为“标准答案”。
- 中间核心框:判别器 (Discriminator - Motion Prior Reward)
- 这是一个“打分老师”。它同时接收两路输入:
- 真数据 (Real Samples): 来自左边的真狗动作(绿色箭头 +1)。
- 假数据 (Fake Samples): 来自右边机器狗自己跑出来的动作 (红色箭头 -1)。
- 任务: 判别器试图区分哪个是真的,哪个是假的。如果机器狗骗过了判别器,就能拿到很高的风格奖励 。
- 这是一个“打分老师”。它同时接收两路输入:
- 右侧与闭环:策略网络 (Policy) 与 训练
- Policy: 这是机器狗的大脑。它接收环境状态 和人类给的任务指令 (比如“向前跑”)。
- Environment: 机器狗在模拟器里执行动作 ,产生新的状态。
- 求和 (): 最终,机器狗收到的反馈是 风格奖励 (, 动作像不像狗) 加上 任务奖励 (, 跑得快不快) 。机器狗通过强化学习(PPO算法)不断优化自己,试图同时最大化这两个分数。
核心技术
Adversarial Motion Priors (AMP)
这是一种基于生成对抗网络 (GAN) 思想的技术 。它用一个判别器来替代人工设计的复杂物理约束奖励。它把“什么样的动作是自然的”这个问题,转化成了“让判别器认为是真的”这个问题
- 替代了复杂的人工奖励: 不再需要手动调节那 13 个参数,只需要提供几秒钟的动作数据 。
- 实现了 Sim-to-Real (虚实迁移): 以前只用简单的任务奖励训练出来的狗,在模拟器里会利用物理引擎的 Bug 疯狂震动(Jittery behaviors),在真机上根本用不了。AMP 强迫它学真狗的动作,所以学出来的策略很稳,能直接上真机 。
- 自动涌现自然步态: 不需要硬编码规则,机器狗自己学会了慢走用 Pace,快跑用 Canter 。
实验分析
-
能量效率对比 (Cost of Transport, COT):
- 作者特意测量了机器狗跑动时的能耗(Table II)。
- 结论: 使用 AMP 训练的策略,COT(约 0.93-1.12)显著低于人工设计奖励(1.37-1.41),更远低于无风格奖励(>5.0)。这证明模仿真狗的动作不仅好看,而且最省力 。
-
步态转换机制 (Gait Transitions):
- 作者分析了 Fig.。重点展示了当速度指令从 1m/s 增加到 2m/s 时,机器狗自动改变了脚的落地模式(从 Pace 变成 Canter),且这种改变导致了能耗的优化。这证明 AMP 学到了动物运动的本质逻辑 。
-
真实世界的鲁棒性:
- 作者强调了在没有专门针对真机微调的情况下,策略能处理复杂的真实地形和外力干扰。

Written by
ZZC
每天研究怎么摸鱼的神人
Comments
评论功能即将上线