操作系统
Lec9: Virtual Memory
请求调页、页面置换算法(FIFO/Optimal/LRU/Clock)、帧分配策略、抖动与工作集模型。
Virtual Memory
这一章与上一章有什么区别呢?我的理解如下:
- 上一张强调的是 virtual address 和 physical address 的映射关系,是在内存分配好了的情况下进行的。
- 这一章我们的任务是在程序刚开始的时候,我们怎么将程序加载进内存中去。
以上是我的理解,不一定正确,可能需要修改。
Background
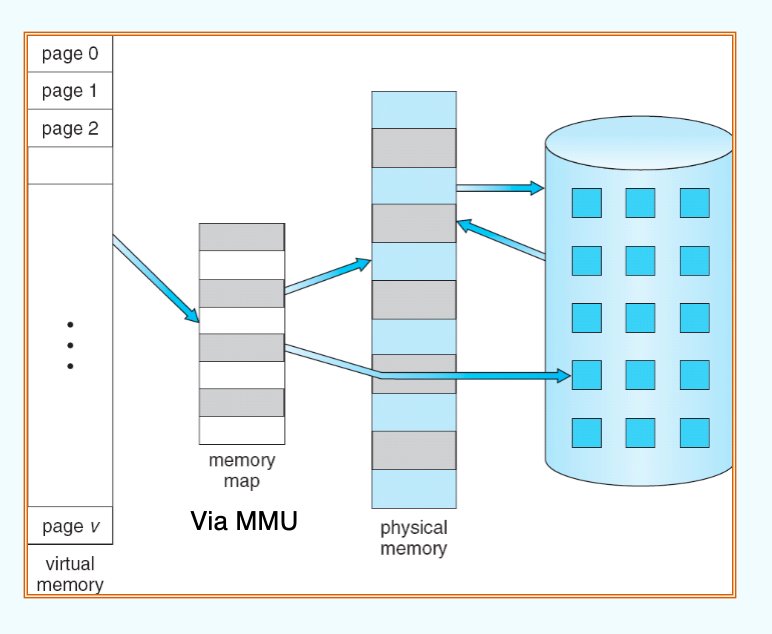
- Virtual memory – separation of user logical memory from physical memory.
- Only part of the program needs to be in memory for execution
- Logical address space can therefore be much larger than physical address space
- Allows address spaces to be shared by several processes
- 允许共享部分物理地址,实现资源共享
- Allows for more efficient process creation
- 允许进程更快被创建(分配的资源减少)
- 实际上,对于一个正在运行的程序来说,很多地方都是用不到的。因此,程序员在进行程序设计的时候,可以开出很大的内存。这也是虚拟内存的由来(比物理内存大很多甚至是几倍)
那么,什么是 virtual memory 呢?下面的一段定义相当精辟:
virtual memory isn’t a physical object, but refers to the collection of abstractions and mechanisms the kernel provides to manage physical memory and virtual addresses.
virtual memory 怎么实现呢?
- Virtual memory can be implemented via:
- Demand paging
- Demand segmentation
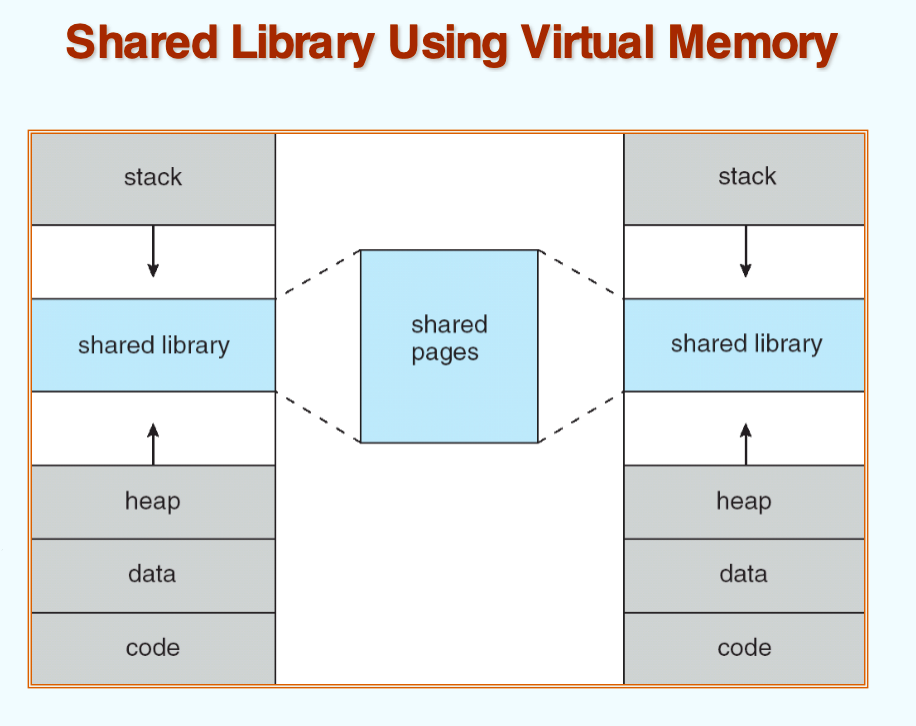
Other benefits
- System libraries can be shared by several processes through mapping of the shared object into a virtual address space
- Shared memory is enabled
- Pages can be shared during process creation (speeds up creation)
Demand Paging
为什么我们需要 Demand Paging 这个技术呢?这是因为我们想让程序员的编程更简单,不需要考虑内存问题。
从磁盘加载可执行程序到内存的方法有很多。最简单的一种方法是在程序执行的时候将整个程序加载进物理内存。然而,这种方法的一个问题是,最初可能不需要整个程序都处于内存。
另外一种方法是仅在需要时才加载页面,这种技术被称为 demand paging(请求调页)。对于请求调页的虚拟内存,页面只有在程序执行期间被请求时才会被加载,因此,从未访问的那些页从不加载到物理内存中。
- Bring a page into memory only when it is needed
- Less I/O needed
- Less memory needed
- Faster response
- More users
- Page is needed => reference to it
- invalid reference => abort
- not-in-memory => bring to memory
- Lazy swapper – never swaps a page into memory unless page will be needed
- 在这个方法中,我们采用惰性交换器:“非必要不交换”
- Swapper that deals with pages is a pager
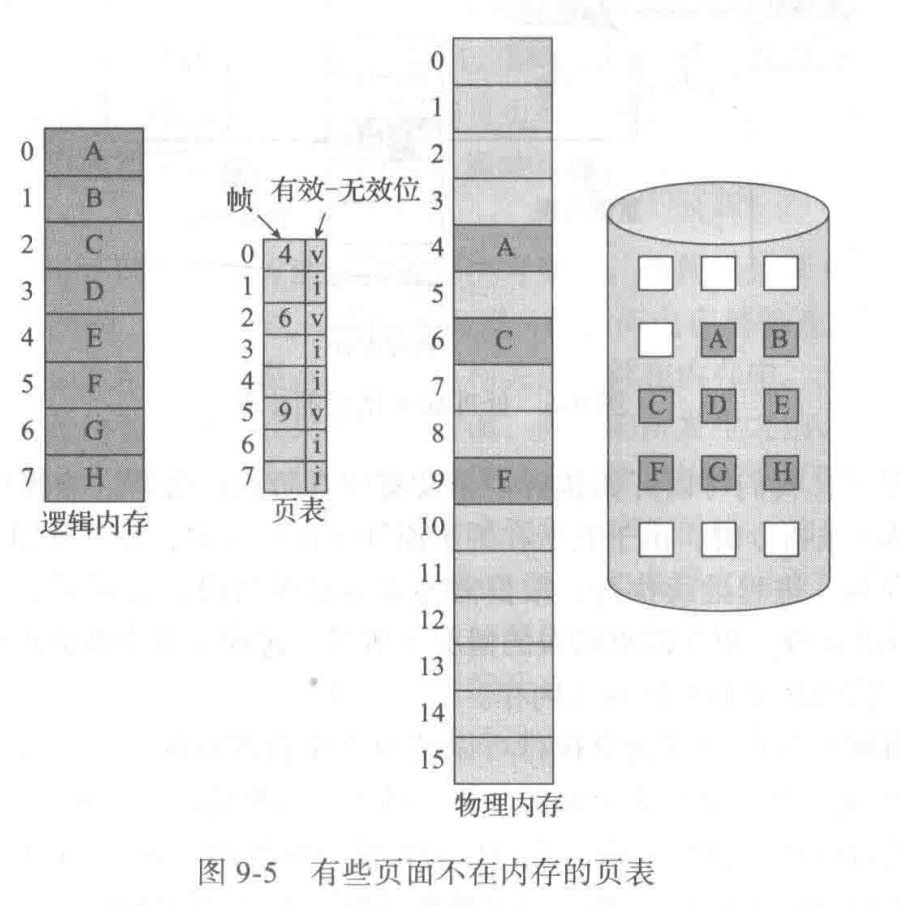
接下来,我们讲一讲 Demand Paging 的运行机制。当换入进程的时候,调页程序会猜测在该进程被再次调用之前会用到哪些页,并将这些页调入内存。显而易见的是,使用这种方案需要一系列的硬件支持,来区分内存的页面和磁盘的页面,我们可以采用之前说过的“有效-无效位”的方案。
- With each page table entry a valid–invalid bit is associated(v => in-memory, i => not-in-memory)
- Initially valid–invalid bit is set to i on all entries
- Example of a page table snapshot:
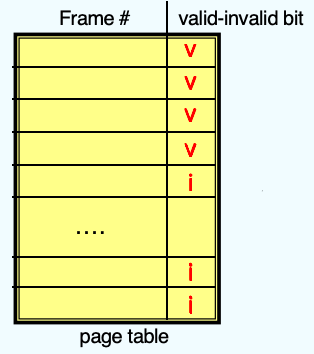
- During address translation, if valid–invalid bit in page table entry is i => page fault (a trap to the OS)
在 valid 的情况下,显然页面已存在在内存中了,可以正常运行。然而,在 invalid 的情况下,则会出现两种情况:
- 页面无效,机器地址不在进程的逻辑地址中(base~base+limit)
- 有效但只在磁盘上,没有被调进内存中
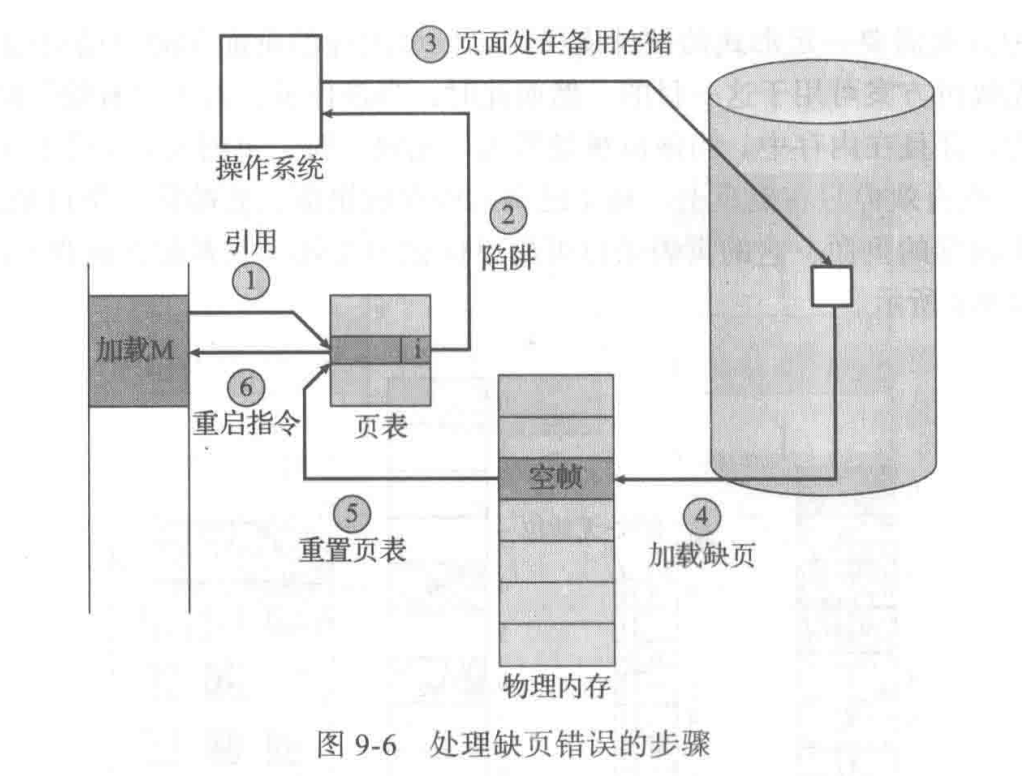
对于 invalid 的情况,我们采用一个中断程序(trap) page fault 来进行处理。
- If there is a reference to a page, first reference to that page will trap to operating system:
- page fault
- Operating system looks at another table (kept with PCB) to decide:
- Invalid reference => abort
- Just not in memory
- Get empty frame
- Swap page into frame
- 需要看是否有 free frame,若没有,需要腾出一个,这是后面的内容
- Reset tables
- Set validation bit = v
- Restart the instruction that caused the page fault
实际上,以上操作的后半段(交换页面的操作)并不是由 page fault 这个 trap 完成的,因为 trap 要求很快,但 swap 很慢(有I/O),因此需要 bottom-half 来解决,swapper 就是一种 bottom-half
我们可以使用加载第一条指令所在的 page 来达到快速启动进程的方法
Performance of Demand Paging

- 其中,==page fault overhead + swap page out + swap page in + restart overhead = page-fault service time==
Copy-on-Write
- Copy-on-Write (COW) allows both parent and child processes to initially share the same pages in memory
- If either process modifies a shared page, only then is the page copied
- COW allows more efficient process creation as only modified pages are copied
- Free pages are allocated from a pool of zeroed-out pages


Page Replacement
在之前的内容中,我们提到了,在页面有效但不在内存中时,我们需要将页面换进内存中,也就是下面的过程:
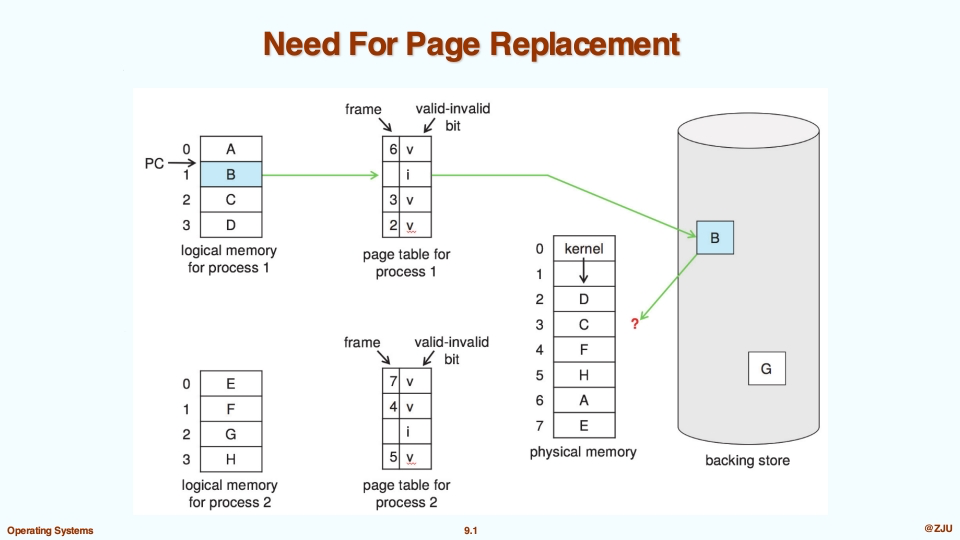
- Page replacement – find some page in memory, but not really in use, swap it out
- algorithm
- performance – want an algorithm which will result in minimum number of page faults
- 我们的目标之一就是在交换完之后,发生 page fault 的次数尽量小,也可以这么说,交换完之后,被换出去的页面的访问次数尽量少。
- Same page may be brought into memory several times
- Prevent over-allocation of memory by modifying page-fault service routine to include page replacement
- Use modify (dirty) bit to reduce overhead of page transfers – only modified pages are written to disk
- Page replacement completes separation between logical memory and physical memory – large virtual memory can be provided on a smaller physical memory


- 我们称被选择交换的帧为 victim frame
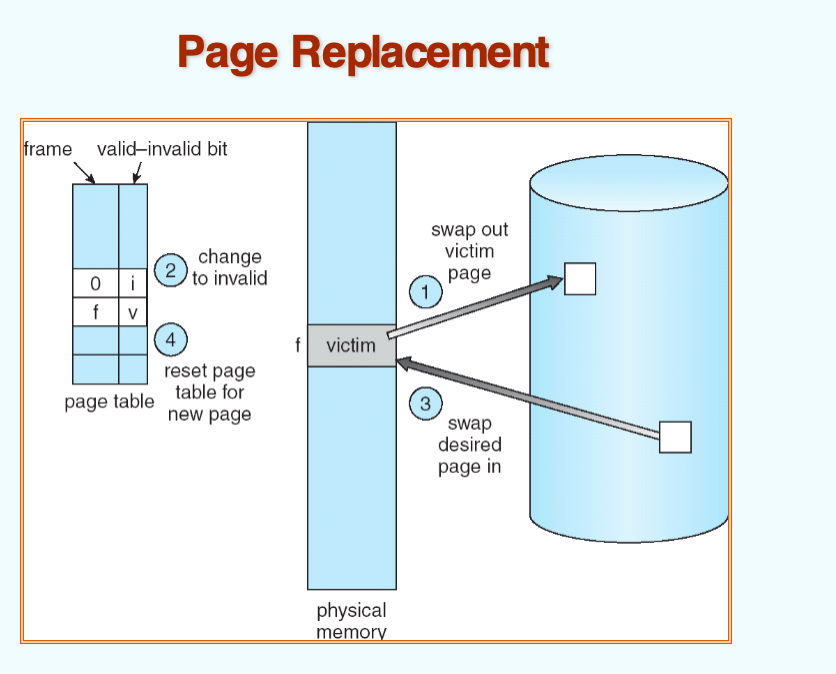
Algorithm
为了实现请求调页,必须要解决两个主要问题:
- free-allocation algorithm:帧分配算法:若有多个进程在内存中,必须决定要为每个进程分配多少帧
- page-replacement algorithm:页面置换算法:当需要页面置换的时候,必须选择要置换的帧。
一般来说,我们想要的是一个 page fault rate 最小的算法。

FIFO 页面置换

- 就是很简单的 First-in-First-out 的算法,使用一个队列进行维护
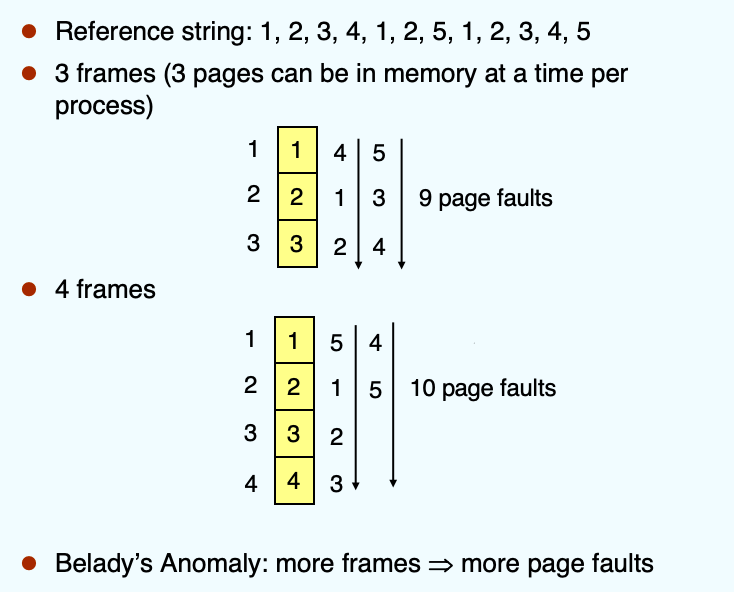
Belady 异常


Optimal Algorithm

- 思路:替换策略是替换最长时间不被使用的 page
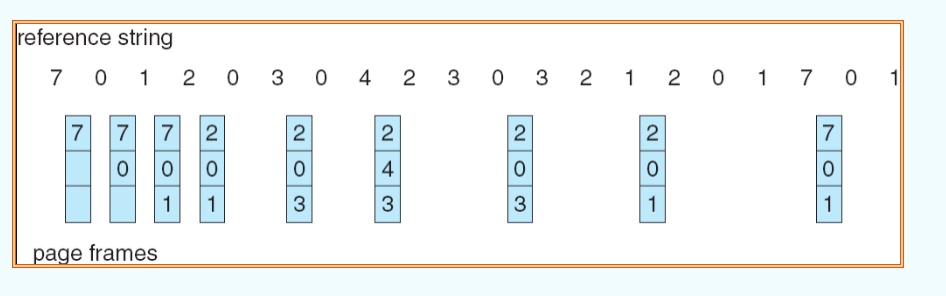
上面展示的例子详细说明了这个策略是怎么运作的:每一次更新 reference string 的时候,都会向“未来”观看,寻找 reference string 中最长时间不使用的 page,将其作为 victim 替换出去,并且换入新的 page。
Least Recently Used (LRU) Algorithm
显而易见的是,Optimal Algorithm 需要 reference string 的未来知识,这个问题在之前出现过类似的,就是 SJF 的 CPU 调度。这里我们采用一种更为可行的方法,也是之前很多课程中都有提及的算法:最近最少使用算法(LRU)。
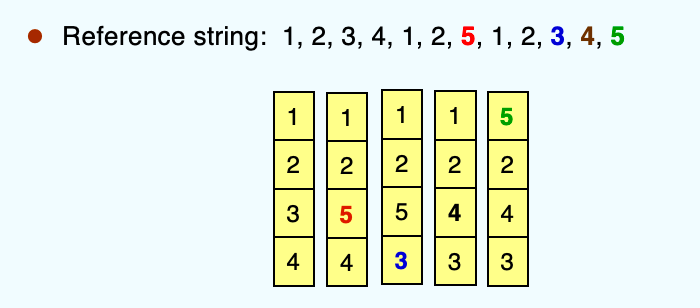
对于 LRU,有两种比较常见的实现方法:
- Counter implementation
- Every page entry has a counter; every time page is referenced through this entry, copy the clock into the counter
- When a page needs to be changed, look at the counters to determine which is to change
- 也就是说我们对每一个 PTE 都定义一个 counter,用于记录上一次调用时间,并在每次引用的时候都寻找 counter 最小(时间离得最远)的 PTE,作为 victim 交换出去
- Stack implementation – keep a stack of page numbers in a double link form:
- Page referenced:
- move it to the top
- requires 6 pointers to be changed
- No search for replacement
- Page referenced:
和 Optimal Algorithm 一样,LRU 置换没有 Belady 异常。这两者都属于同一种算法,称为堆栈算法。



LRU Approximation Algorithms
然而,在实际的情况下,很少能有计算机系统提供足够的硬件来支持真正的 LRU 算法。因此,我们考虑使用近似 LRU 页面置换算法来解决这个问题。
一般而言,我们有两种方法来实现这个算法:
- Reference bit
- With each page associate a bit, initially = 0
- When page is referenced bit set to 1
- Replace the one which is 0 (if one exists)
- We do not know the order, however

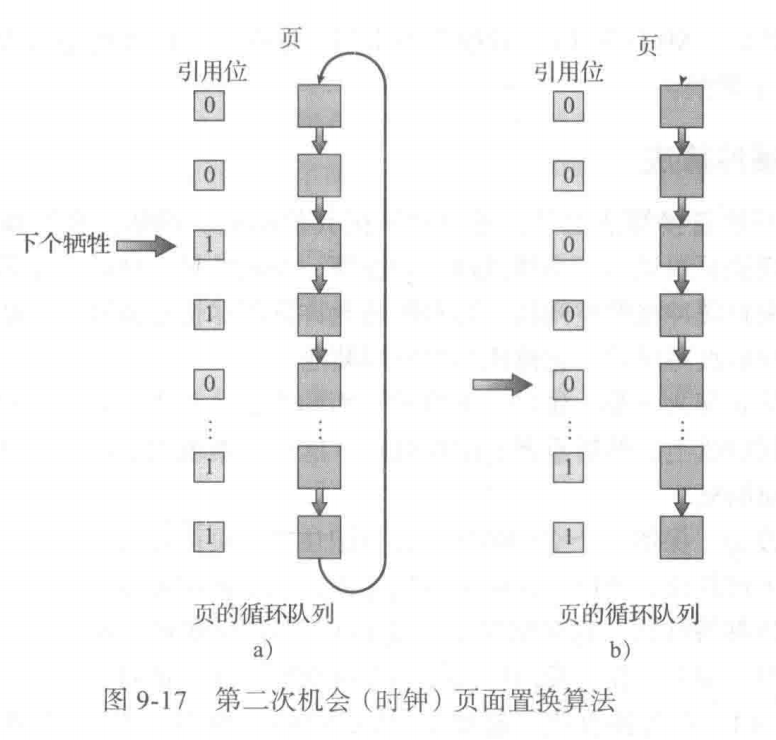
- Second chance
- Need reference bit
- Clock replacement
- If page to be replaced (in clock order) has reference bit = 1 then:
- set reference bit 0
- leave page in memory
- replace next page (in clock order), subject to same rules


Counting-based Algorithms
- Keep a counter of the number of references that have been made to each page
- LFU Algorithm: replaces page with smallest count
- MFU Algorithm: based on the argument that the page with the smallest count was probably just brought in and has yet to be used


Allocation of Frames
我们知道,在启动一个进程的时候,需要有一个最小数量的 pages,用于程序的运行。
- Each process needs minimum number of pages - usually determined by computer architecture.
- Example: IBM 370 – 6 pages to handle Storage-to-Storage MOVE instruction:
- instruction is 6 bytes, might span 2 pages
- 2 pages to handle from
- 2 pages to handle to
- Two major allocation schemes
- 有两种常见的分配方式:
- fixed allocation
- priority allocation
Fixed Allocation

- 分为两种方案:
- Equal allocation
- 每个进程分配到的 frame 都是相等的
- Proportional allocation
- 根据每个进程的大小分配可用的内存
- Equal allocation
Priority Allocation
- Use a proportional allocation scheme using priorities rather than size
- If process Pi generates a page fault,
- select for replacement one of its frames
- select for replacement a frame from a process with lower priority number
Global vs. Local Allocation
-
Global replacement – process selects a replacement frame from the set of all frames; one process can take a frame from another
-
Local replacement – each process selects from only its own set of allocated frames
-
Problem with global replacement: unpredictable page-fault rate. Cannot control its own page-fault rate. More common
- 会有刚好的系统吞吐量
-
Problem with local replacement: free frames are not available for others. – Low throughput


Thrashing
- If a process does not have “enough” pages, the page-fault rate is very high. This leads to:
- low CPU utilization
- Queuing at paging device, the ready queue becomes empty
- operating system thinks that it needs to increase the degree of multiprogramming
- another process added to the system
- Thrashing = a process is busy swapping pages in and out
也就是说,若一个进程没有足够的 pages,会导致 page fault rate 很高,也就会导致 CPU 的利用率。同时,因为大量的 swapping 操作,进程会在 paging device 处变得拥挤,但 ready queue 会变得空闲,导致 OS 认为需要增加 degress of multiprogramming,也就是进程的数量,导致又一个进程被加入到系统中,恶性循环。这就是 Thrashing,也就是系统抖动。
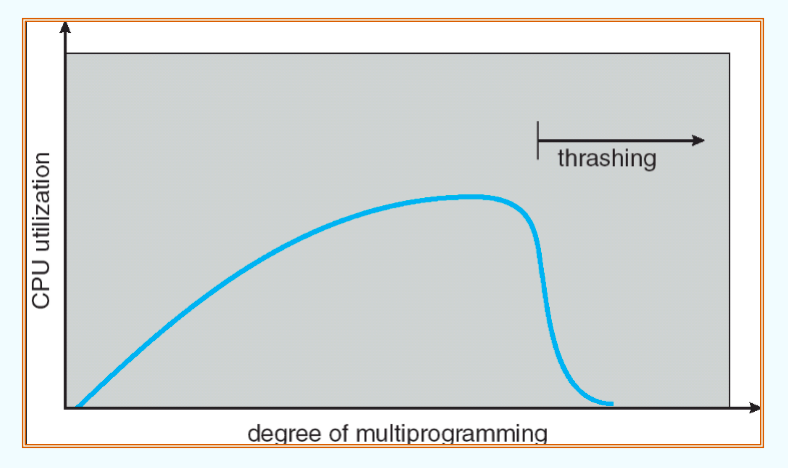
以上是 Thrashing 的示意图。
Demand Paging and Thrashing
- Why does demand paging work?
- Locality model
- Process migrates from one locality to another
- Localities may overlap
- Why does thrashing occur?
- ∑ size of locality > total memory size
- 实际上,正如上面所说的一样,出现 thrashing 的根本原因是 ∑ size of locality > total memory size,也就是要访问局部空间大于所分配的空间,这就导致了一致的 page fault
- To limit the effect of thrashing: local replacement algo cannot steal frames from other processes. But queue in page device increases effective access time.
- To prevent thrashing: allocate memory to accommodate its locality
为了提高 CPU 的利用率并停止抖动,我们必须降低多道程序程度。有两种方法可以解决这个问题:
- local replacement algorithm:局部置换算法。
- priority replacement algorithm:优先权置换算法。

Working-Set Model
为了防止抖动,应该为进程提供足够多的所需要的 frame。但我们怎么知道 frame 的数量呢?这里我们使用一个名叫 working-set model 的方法







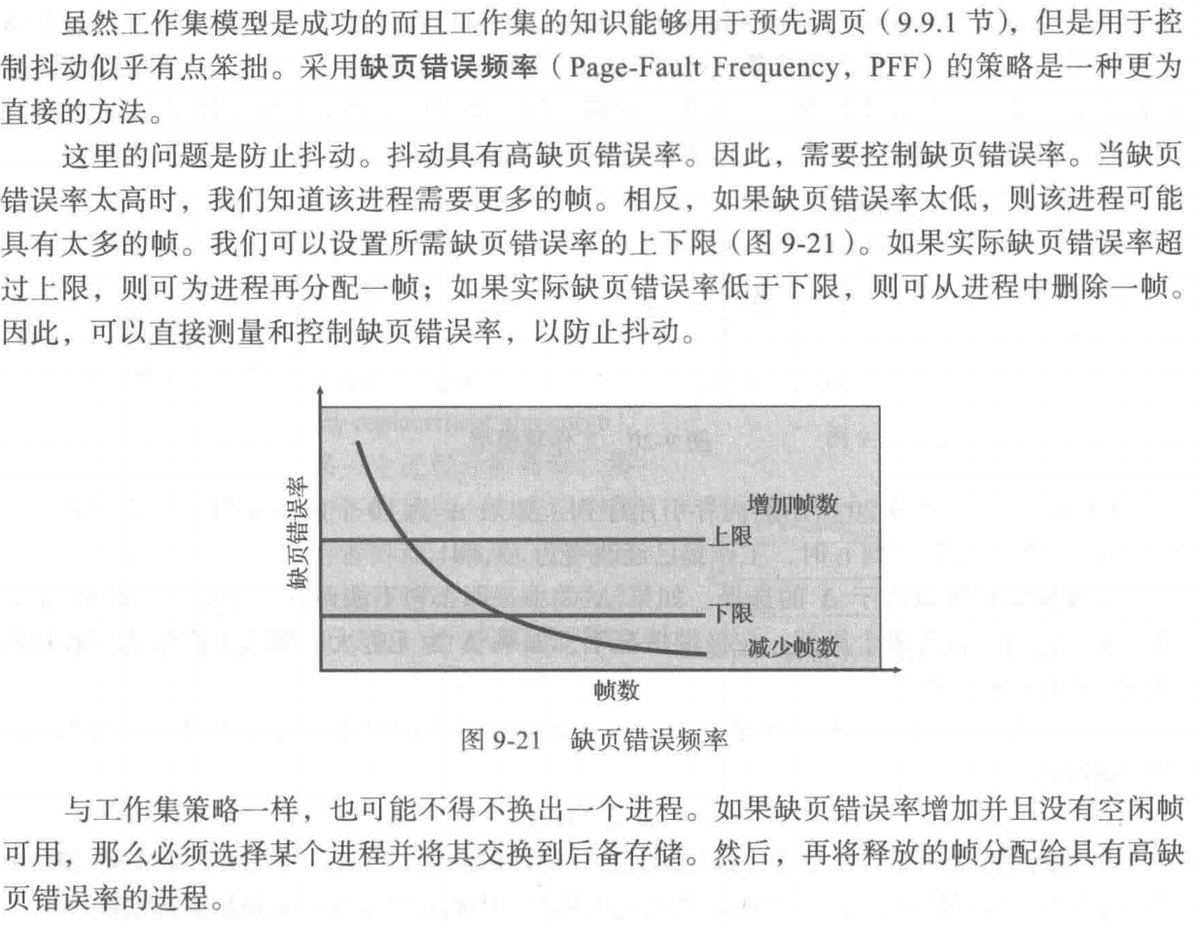
Page-Fault Frequency Scheme
- Establish “acceptable” page-fault rate for each process
- If actual rate too low, process loses frame
- If actual rate too high, process gains frame
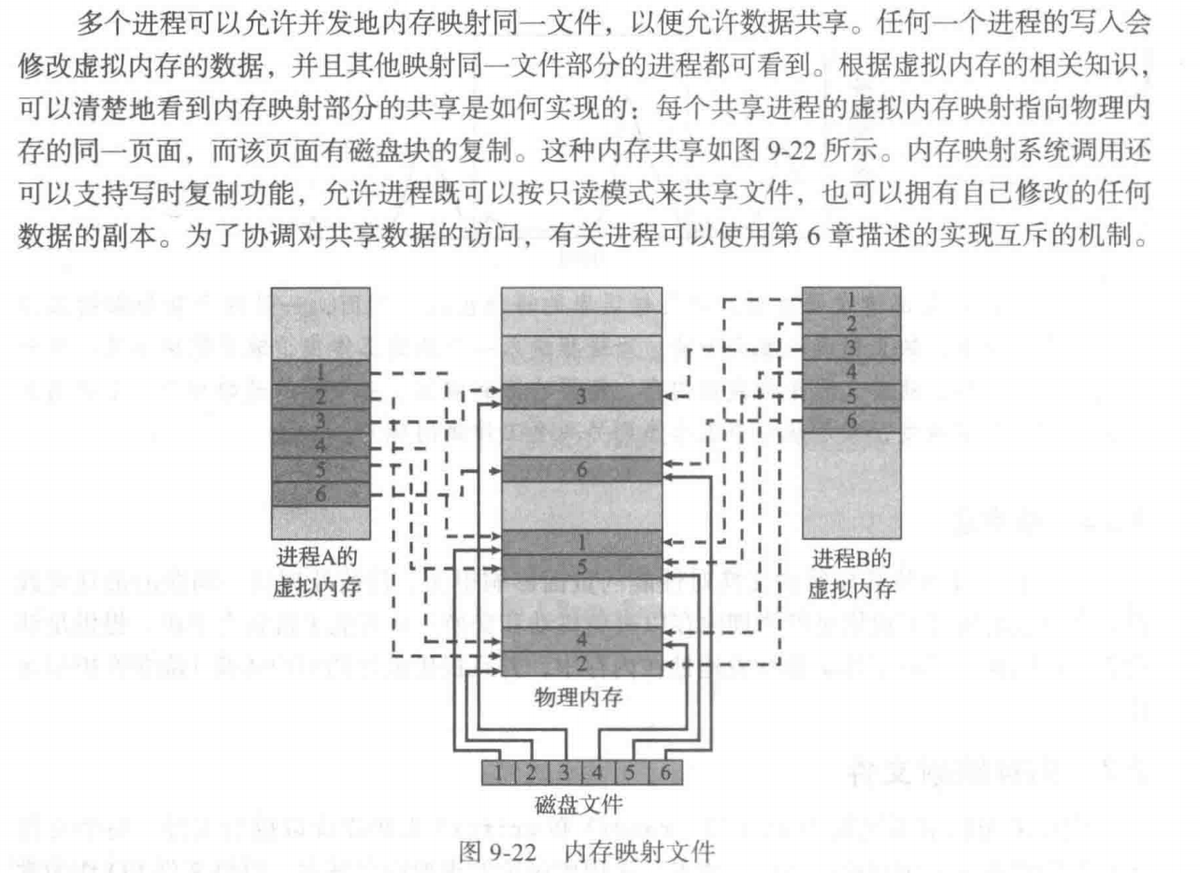
Memory-Mapped Files
- Memory-mapped file I/O allows file I/O to be treated as routine memory access by mapping a disk block to a page in memory
- A file is initially read using demand paging. A page-sized portion of the file is read from the file system into a physical page. Subsequent reads/writes to/from the file are treated as ordinary memory accesses.
- Simplifies file access by treating file I/O through memory rather than read() write() system calls
- Also allows several processes to map the same file allowing the pages in memory to be shared

Allocating Kernel Memory
- Treated differently from user memory
- Often allocated from a free-memory pool
- Kernel requests memory for structures of varying sizes – needs to reduce fragmentation
- Some kernel memory needs to be contiguous (certain h/w device interacts with contiguous physical memory)
- Therefore, many systems do NOT utilize paging for kernel code and data.

对于上述问题,我们有两种解决方法:
- buddy system
- Slab Allocator
buddy system

Slab Allocator



Written by
ZZC
每天研究怎么摸鱼的神人
Comments
评论功能即将上线