操作系统
Lec3: Processes
进程的概念、PCB 结构、进程状态转换、进程调度,以及进程间通信(IPC)。
Processes
.png)
Process Concept
在本课程中,我们认为 job 一词和 process 是等价的
进程运行需要一点东西:
- Code/Text section:程序代码,code
- Program counter:记录程序执行到哪里
- Stack:用于存储函数调用时的临时数据,function parameters,local vars,return adresses
- Data Section:global vars
- Heap:动态分配的内存
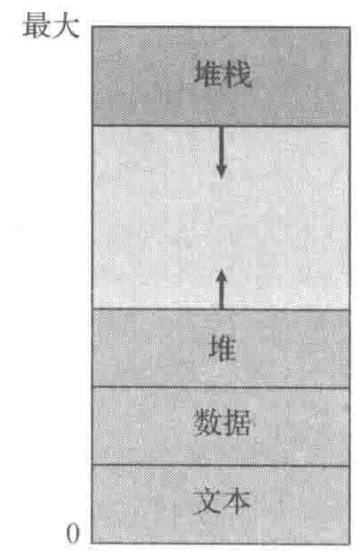
- 上图的地址都是虚拟地址。
- 蓝色的区域称为空洞(address space),空洞会很大,因此 memery 会变得很稀疏
Process State
进程可以有很多的状态:
- new:进程正在被创建
- running:进程正在执行
- waiting:进程等待发生某个事件(如 I/O 完成或者收到信号)
- ready:进程等待分配处理器
- terminated:进程已经完成执行
这些状态可以进行转化,我们使用一张有向图来表示。
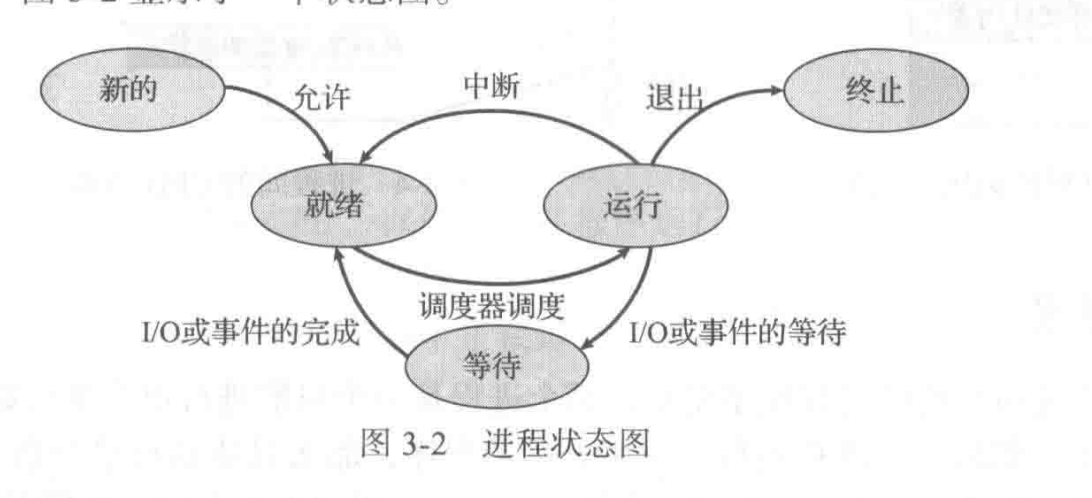
Q:waiting 状态为什么不能直接进入 running?
Process Control Block(PCB)


有时候,我们需要把上面的有关 Process 的信息全部记录下来,我们把这些信息的集合称为 Process Control Block(PCB)。
衡量 PCB 的标准是恢复后进程的状态是不是和之前一样。
以下是 PCB 的一个例子:
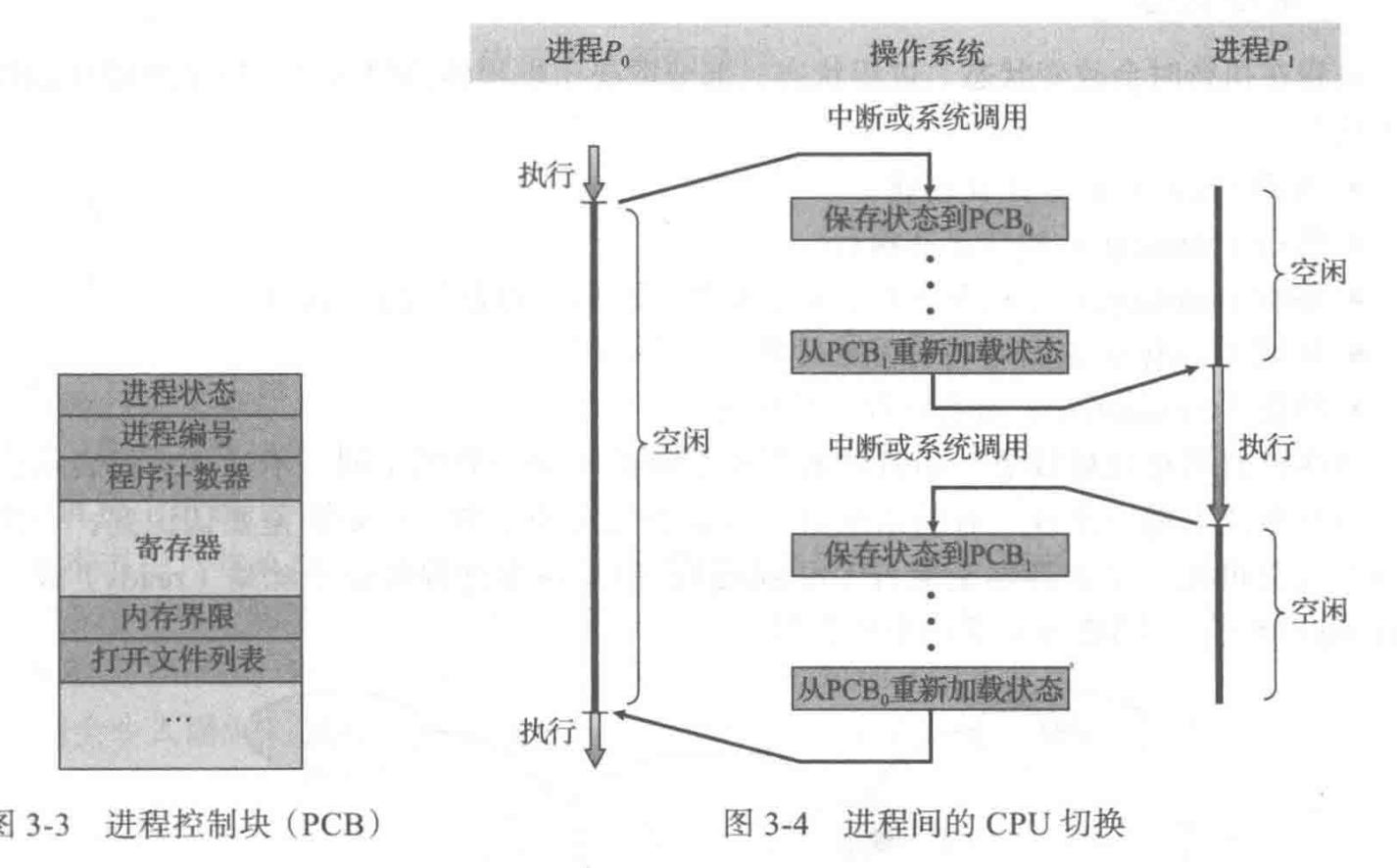
- Kernel 中的 Scheduler 是用来选择下一个运行的进程。被选择的进程是在 ready 的状态的。Scheduler 会有一个表,专门用于存储 ready 状态的进程。
- 空闲(idle)部分时,process 不运行。
- 从前一个进程中断开始,到下一个进程准备启动,这个过程被称为 Context Switch。
- 如果我们需要 resume 一个 process 的话,我们最需要的是 CPU state information。
- 如果我们仅仅只是处理一个 interrupt 而不是切换进程的话,我们只需要存储一些关键信息就好了,比如 PC counter,Stack pointer,general purpose register。也就是说,上面那张图只会发生在进程切换的时候。
Process Scheduling Queues
对于 PCB 来说,我们可以使用 queue 来进行管理。
-
Job queue - set of all processes in the system
- 系统中所有的进程都可以通过 Job queue 连起来
-
Ready queue - set of all processes residing in main memory, ready and waiting to execute
-
Device queue - set of processes waiting for an I/O device
-
Processes migrate among various queues
以下是这些队列的示意图,进程在这些队列中迁移。
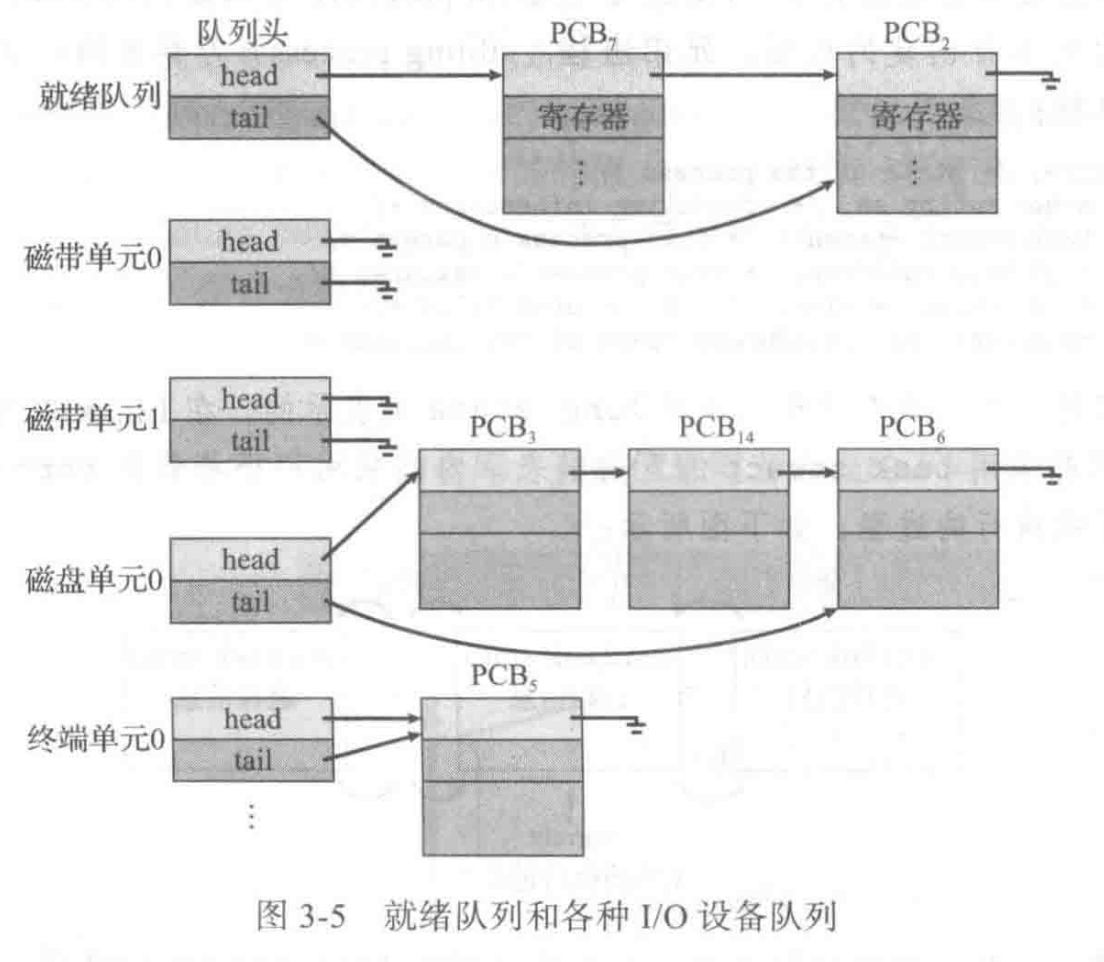
- 如上图所示,每一个被链接起来的 PCB 与正在运行的进程一一对应,通过操控 PCB,我们可以控制进程的运行状态。这整个过程由 kernel 决定。
- 每个设备都有自己的 queue。
- 只需要等待 CPU 的队列我们叫 ready queue。
- 对我们来说,ready queue 和 device queue 是比较重要的。
Representation of Process Scheduling
进程调度通常使用队列图(queueing diagram)来表示。
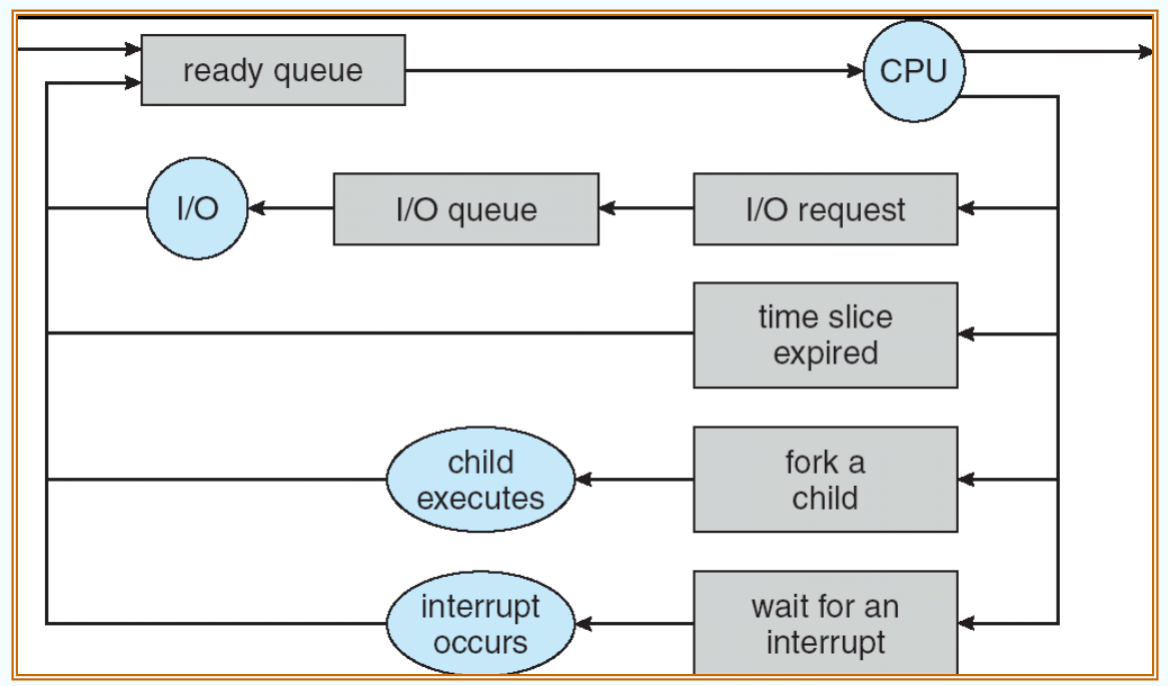


- 我们之前常说的 Schedular 实际上就发生在 ready queue 之后。
Schedular
- Long-term scheduler (or job scheduler) – selects which processes should be brought into memory (the ready queue)
- 也就是从外存中选择一个进程搬进内存中。
- 相比于以前,现在更多地是我们人类自己进行一个任务分配,也就是进行一个长期调度。
- 控制多道程序程度(degree of multiprogramming),也就是内存中的进程数量
- Long-term scheduler is invoked very infrequently (seconds, minutes) --> (may be slow)
- Short-term scheduler (or CPU scheduler) – selects which process should be executed next and allocates CPU
- 也就是在 ready queue 中选择下一个要执行的进程。
- Short-term scheduler is invoked very frequently (milliseconds) --> (must be fast)
- 发生频繁,以满足 time sharing
-
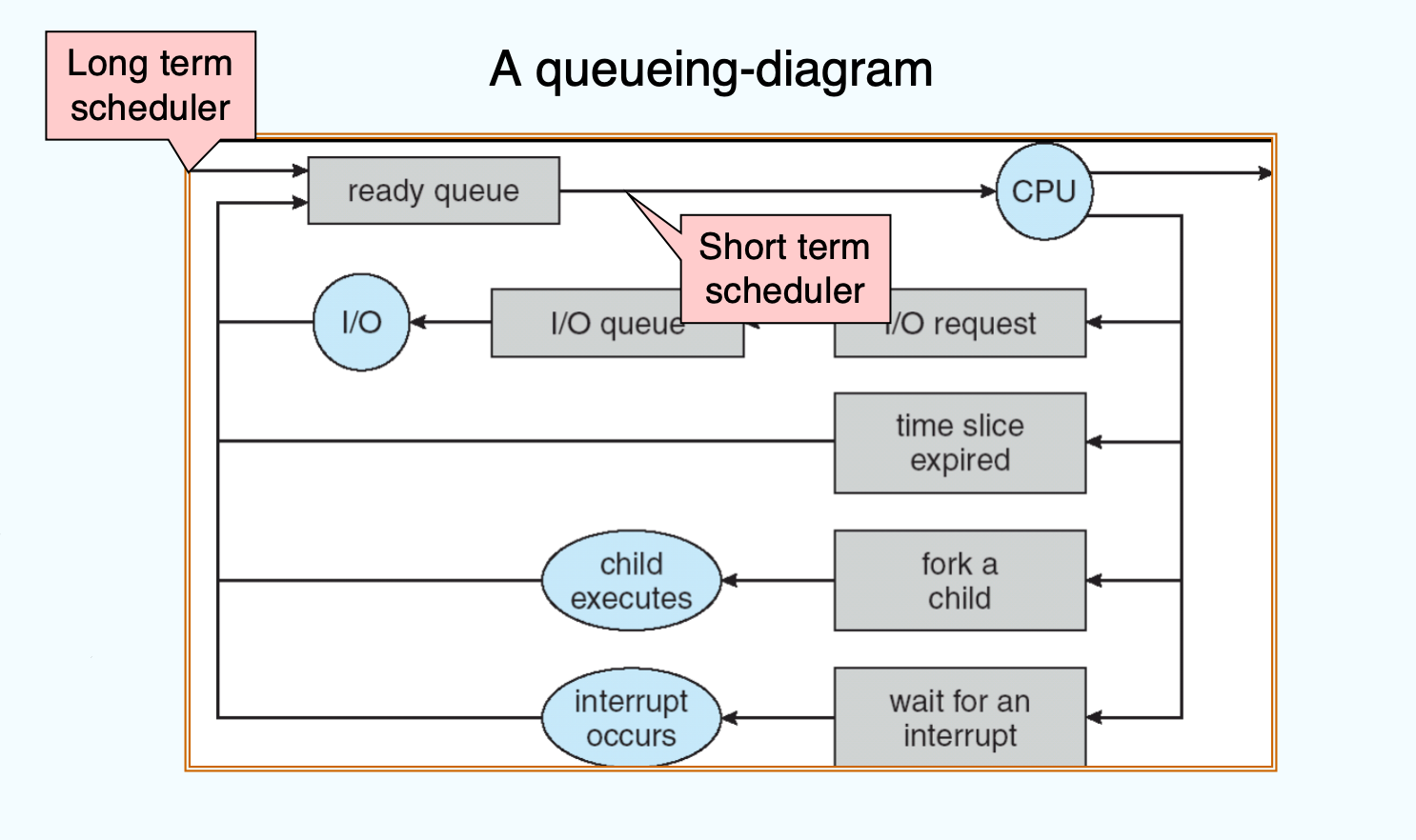
- Medium-term Schedular
-
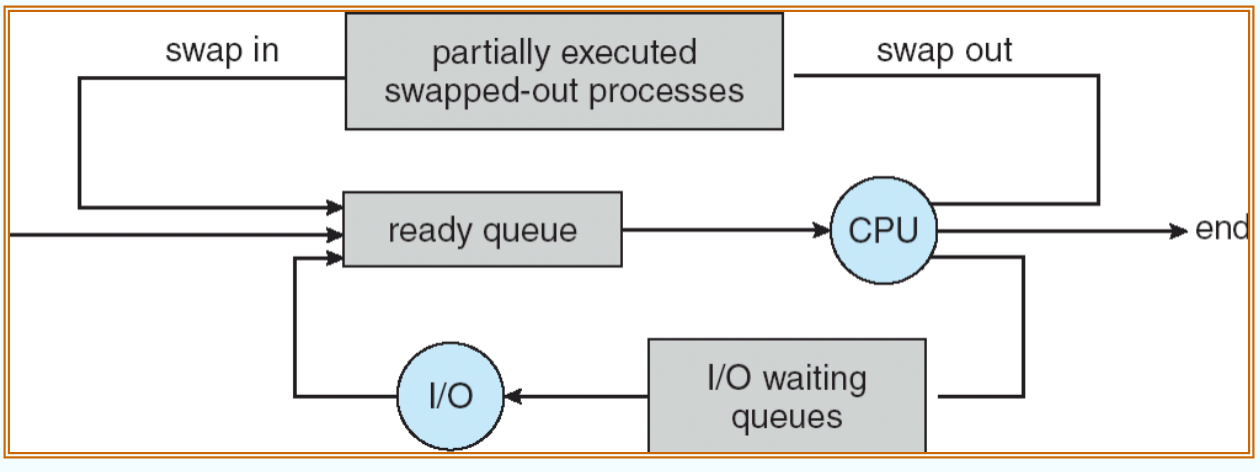
- 有时候,会出现内存(CPU)不够使用的情况,这个时候,我们就会把进程从其中移出,从而降低多道程序程度。之后,进程可以重新调入进内存,并从中断处重新运行。这种方式叫做交换,这种方式叫做交换(swap)。进程可以换出(swap out),也可以换进(swap in)。
-
Class of Process
- Processes can be described as either:
- I/O-bound process – spends more time doing I/O than computations, many short CPU bursts
- CPU-bound process – spends more time doing computations; few very long CPU bursts
Context Switch
-
When CPU switches to another process, the system must save the state of the old process and load the saved state for the new process
-
Context-switch time is overhead; the system does no useful work while switching - typically takes milliseconds
- 在 Context Switch 的这段时间里,机器并没有做任何有意义的事情,因此这一部分花费的时间完全就是开销
-
Time dependent on hardware support. In the SPARC architecture, groups of registers are provided.
- 越复杂的操作系统,上下文切换的时候所要用到的 Register 越多。当所需要的数量过大的时候,就会将寄存器写入内存中。
Process Creation
父进程创造出子进程,子进程再创造,如此往复,形成一棵进程树。
- Resource sharing
- Parent and children share all resources
- Children share subset of parent’s resources
- Parent and child share no resources
- Execution
- Parent and children execute concurrently
- Parent waits until children terminate
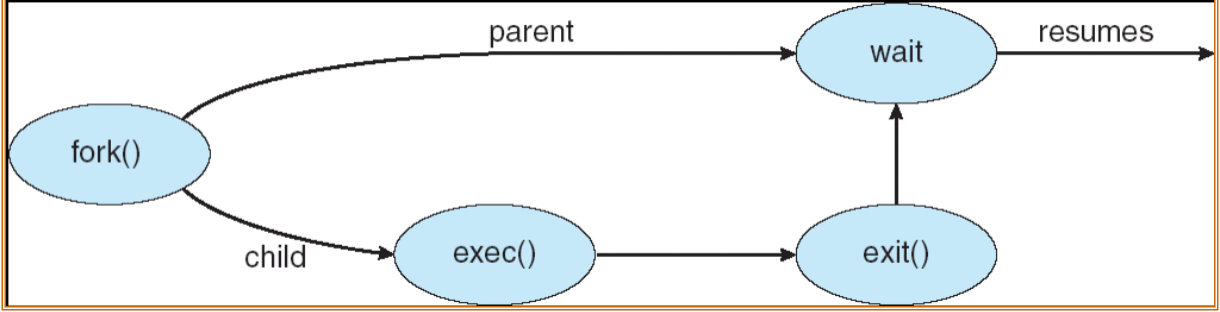
- Address space
- Child duplicate of parent
- fork()
- Child has a program loaded into it
- exec()
- (首先)子进程作为父进程的副本被创建(拥有相同的地址空间),(随后)子进程的地址空间中加载入了一个新的程序(以执行新的任务)。
- Child duplicate of parent
- UNIX examples
- fork system call creates new process
- exec system call used after a fork to replace the process’ memory space with a new program
- 上图中的 fork 代表父进程分枝出子进程。
- 每一个进程都有一个进程编码,我们称为 pid (process id)。子进程还有一个 ppid,代表父进程的 pid。
- 在父进程刚刚创建子进程后,父子进程的内存视图、执行代码等都是相同的。子进程在调用 exec() 系统调用后会将自己的 memory 替换成新的程序执行。
- exit() 代表结束进程。
下面展示一段示例代码:
int main()
{
pid_t pid;
/* fork another process */
pid = fork();
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
exit(-1);
}
else if (pid == 0) { /* child process */
execlp("/bin/ls", "ls", NULL);
}
else { /* parent process */
/* parent will wait for the child to complete */
wait (NULL);
printf ("Child Complete");
exit(0);
}
}
其程序图形化表示如下:
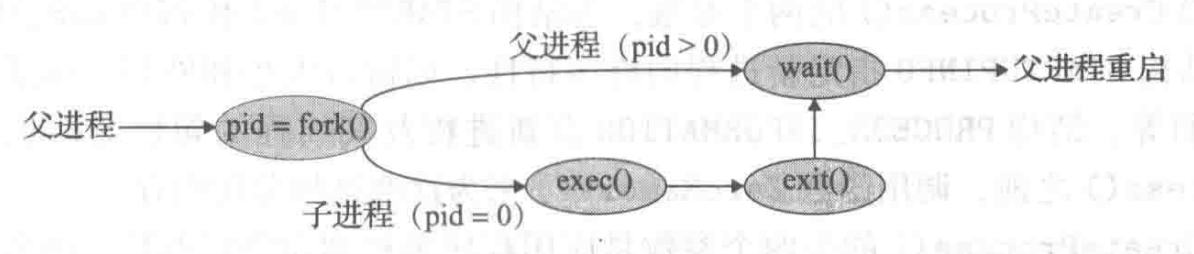
假如出现以下情况:
fork(); // first fork
fork(); // second fork 那么,执行完后会有 4 个进程,第一次执行,父进程产生子进程,第二次,已经有的父进程和子进程再次产生父进程和子进程。
Process Termination
- Process executes last statement and asks the operating system to delete it (exit)
- Output data from child to parent (via wait)
- 子进程返回状态值到父进程
- Process’ resources are deallocated by operating system
- 进程资源被操作系统释放
- Parent may terminate execution of children processes (abort)
- Child has exceeded allocated resources
- Task assigned to child is no longer required
- If parent is exiting
- Some operating system do not allow child to continue if its parent terminates
- All children terminated - cascading termination
- In some other operating systems, the child gets orphaned – and its parent becomes the “init” process (PID=1).
- Some operating system do not allow child to continue if its parent terminates
- Zombie Process and Orphan Process
- Zombie Process :子进程执行完毕并调用
exit()退出,但其父进程没有调用wait()或waitpid()来回收子进程的资源,导致子进程的进程控制块(PCB)仍保留在系统中。 - Orphan Process:父进程在子进程之前终止,子进程失去父进程,此时系统会将其交由
init进程(PID=1)或systemd接管。
- Zombie Process :子进程执行完毕并调用
| 特性 | 僵尸进程 (Zombie Process) | 孤儿进程 (Orphan Process) |
|---|---|---|
| 生死状态 | 已死 (Finished execution) | 活着 (Still running) |
| 父进程状态 | 父进程还活着,但很懒 | 父进程已死 (Terminated) |
| 产生原因 | ==子进程执行了 exit(),但父进程没有执行 wait() 来收尸。== | 父进程在子进程结束前就退出了。 |
| 系统表现 | 占用一个进程号 (PID) 和 PCB,但不占内存/CPU。 | 被 PID 1 (init/systemd) 收养,继续正常运行。 |
| 危害 | 如果由于父进程代码写的烂,产生大量僵尸,会导致PID 耗尽,系统无法创建新进程。 | 通常无害,因为 init 进程非常尽责,会负责回收它们。 |
Cooperating Processes
定义以及优势
- Independent process cannot affect or be affected by the execution of another process
- 若一个进程不能被别的进程影响也不可以影响别的进程,那么我们称这个进程是独立的(independent)
- Cooperating process can affect or be affected by the execution of another process
- 若一个进程能被别的进程影响也可以影响别的进程,那么我们称这个进程是协作的(cooperating)
- Advantages of process cooperation
- Information sharing
- Computation speed-up (Multiple CPUs)
- 对于一个特定的任务,可以将其分为很多的子任务,每个子任务可以和别的子任务一起并行执行。注意,若是如此,计算机需要有多个核。
- Modularity
- 可将系统功能分成独立的进程或者是线程
- Convenience
- 单个用户也可以同时执行很多任务
Interprocess Communication (IPC)
管道
管道是一种常见的 IPC 的实现方式,具体例子如下:
cat employ.csv | column -s',' -t 中间的|即为管道。
- Mechanism for processes to communicate and to synchronize their actions
- 进程之间需要有一种机制,让它们可以交流并同步它们的行为
- Two models for IPC: message passing and shared memory
- Message passing – processes communicate with each other without resorting to shared variables
- 在消息传递中,各个进程通过发送和接收消息来进行交流,而不是通过共享变量或共享内存来交换数据。
- Message-passing facility provides two operations:
- send(message) – message size fixed or variable
- receive(message)
- If P and Q wish to communicate, they need to:
- establish a communication link between them
- exchange messages via send/receive
- Implementation of communication link
- physical (e.g., shared memory, hardware bus)
- logical (e.g., logical properties)
两种方法如下:
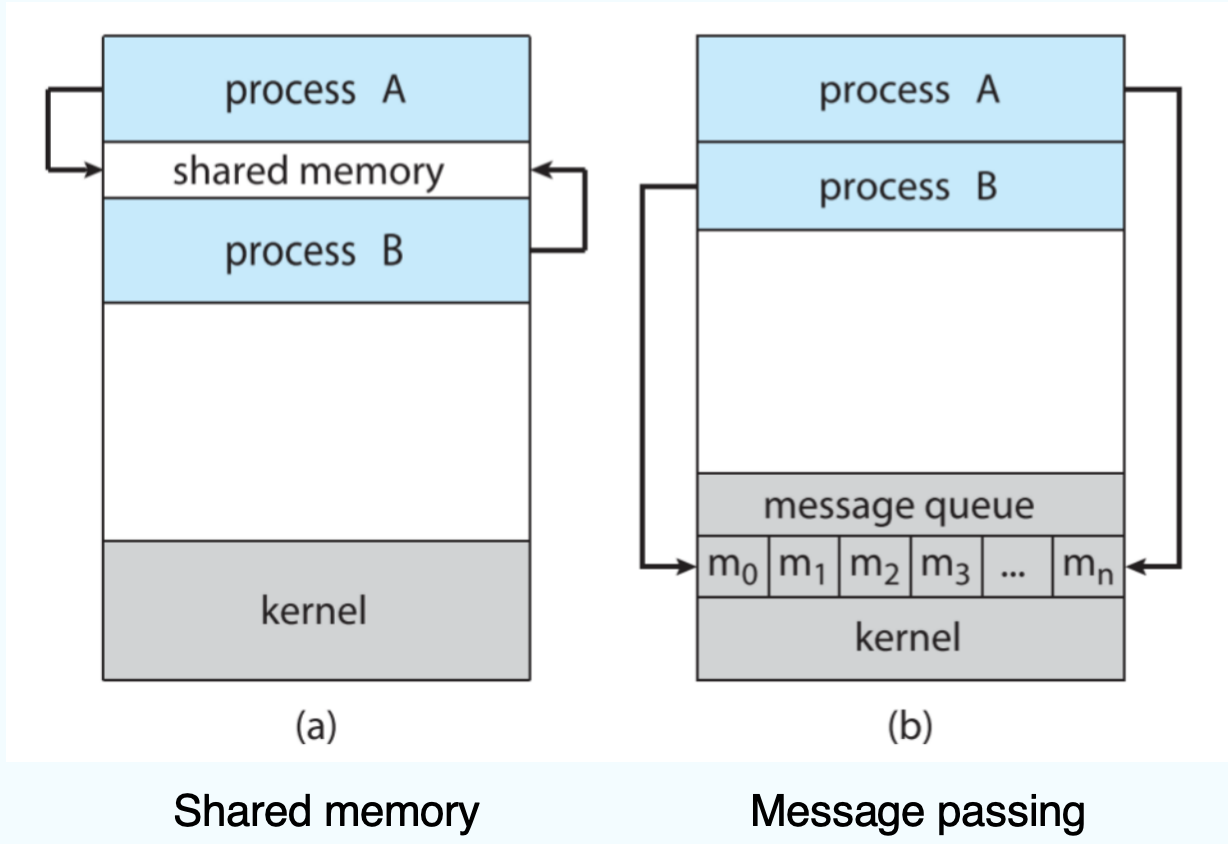
- 这两种方法中,
Shared memory的效率比较高,因为message passing在每次进行的时候都需要进行系统调用,但Shared memory只需要在开始调用就好了。 - 然而,
message passing对于交换较少数据比较适用,因为无需避免冲突;同时,对于分布式系统,message passing也要比Shared memory要容易实现。 - 对于多个处理核,
message passing的性能也要比Shared memory的好。因为共享内存会有高速缓存数据一致的问题。
接下来,我们来讲一讲Message passing 。
Message passing
对于消息传递来说,其提供了一种机制,以方便允许进程不必通过共享地址空间来实现通信和同步。对于分布式环境来说,这特别有用。
消息传递工具提供至少两种操作:
send(message);
receive(message); 如果两个进程需要通信,那么它们必须互相发送信息和接收信息,因此,它们之间必须要有一个通信链路。这里有几个可以实现:
- 直接或间接的通信
- 同步或异步的通信
- 自动或显式的缓冲
direct communication(Naming)
需要通信的进程应有一个方法,可以相互引用。
对于 direct communication,有以下要求:
- Processes must name each other explicitly:
- send (P, message) – send a message to process P
- receive(Q, message) - receive a message from process Q
- Properties of communication link
- Links are established automatically。
- 进程仅需要知道对方的身份就可以进行交流。
- 当两个想要通信的时候,系统会自动建立链接
- A link is associated with exactly one pair of communicating processes
- 一个链接只能建立在一对(两个)进程之间,不能出现第三者
- Between each pair there exists exactly one link
- 每对进程之间只存在一个链接
- The link may be unidirectional, but is usually bi-directional
- 链接可能是无方向的,但大多数时候都是双向的。
- Links are established automatically。

但是也是有缺点的:

inderect communication
因此,接下来就介绍下间接通信(inderect communication):
-
Messages are directed and received from mailboxes (also referred to as ports)
-
这个“邮箱”就是我们现在在使用的“端口”。邮箱可以抽象成一个对象,进程可以向其中存放消息,也可以从中删除消息。
- Each mailbox has a unique id
- Processes can communicate only if they share a mailbox
-
原语如下:
- send (A, message) – send a message to mailbox A
- receive(A, message) - receive a message from mailbox A
-
Properties of communication link
- Link established only if processes share a common mailbox
- A link may be associated with many processes
- Each pair of processes may share several communication links
- Link may be unidirectional or bi-directional

操作系统拥有的邮箱都是独立存在的,不属于某个特定的进程。因此操作系统必须提供机制来允许进程进行如下操作
- create a new mailbox
- send and receive messages through mailbox
- destroy a mailbox

Synchronization
- Message passing may be either blocking or non-blocking
- Blocking is considered synchronous
- Blocking send has the sender blocked until the message is received
- Blocking receive has the receiver block until a message is available
- Non-blocking is considered asynchronous
- Non-blocking send has the sender send the message and continue
- Non-blocking receive has the receiver receive a valid message or null
什么意思呢?其实和前面 I/O 的同步性一块十分类似。以发送为例子,假设有两个进程 A 和 B,A 在给 B 传递信息,Blocking 就是 A 发完之后等 B 收到再继续自己的进程;而 unblocking 就是 A 发完后,不管 B 有没有收到,都直接继续自己的进程。


Buffer
- Queue of messages attached to the link; implemented in one of three ways
- 不管通信是直接还是间接的,通信进程交换的消息总是驻留在临时队列中,简单来讲,队列实现有三种方法:
- Zero capacity – 0 messages
- Sender must wait for receiver
- Bounded capacity – finite length of n messages
- Sender must wait if link full
- Unbounded capacity – infinite length
- Sender never waits
- Zero capacity – 0 messages
- Zero capacity 的情况被称为无缓冲的消息系统,其他情况称为自动缓冲的消息系统。
- Control of Buffering

Shared memory
之后,我们再来讲一讲Shared memory。
- 通常来说,一片共享内存区域会驻留在创建共享内存的进程地址空间内。
- 通常操作系统会阻止一个进程访问另外一个进程的内存,而共享内存需要两个及以上的进程同意取消这一限制。
- 数据的类型和位置取决于进程,而不是受控于操作系统。
- 进程需要确保不会向同一位置同时写入数据。
Producer and Consumer Problem
以下是这个问题的定义:
- Paradigm(范式) for cooperating processes, producer process produces information that is consumed by a consumer process
- 例如,编译器生成的汇编代码可以供汇编程序适用,而汇编程序又可以生成目标模块来供加载程序适用。
解决这个问题的方法之一就是采用共享内存。为了允许生产者和消费者两个进程并发执行,应该有一个可用的缓冲区,给生产者填充或者是消费者清空。
这个缓冲区驻留在生产者进程和消费者进程的共享内存区域。生产者与消费者必须同步,这样的话就不会出现“消费者试图消费一个还未生出的项”的情况。
缓冲区类型可分为两种:
- unbounded-buffer places no practical limit on the size of the buffer. Consumer has to wait if no new item.
- 无界缓冲区
- bounded-buffer assumes that there is a fixed buffer size. Producer must wait if buffer full.
- 有界缓冲区
显然,我们对 bounded-buffer 更感兴趣。那么接下来我们就进行一个比较深入的分析。
首先来看共享内存:
#define BUFFER_SIZE 10
typedef struct {
...
}item;
item buffer[BUFFER_SIZE];
int in = 0;
int out = 0; buffer 是循环数组,用来表示共享内存(缓冲区)。逻辑指针 in 和 out 分别指向换成去的下一个空位和第一个满位。当 in == out 时,缓冲区为空;当 (in + 1)%BUFFER_SIZE == out 时,缓冲区为满。
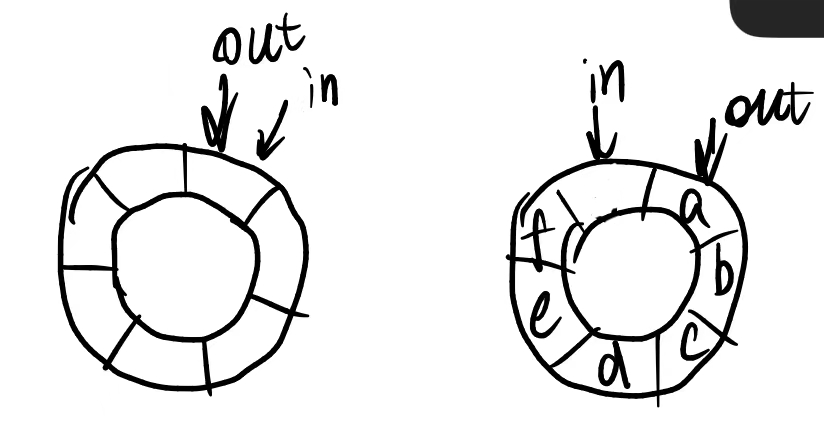
Productor 代码如下:
while (true) {
Produce an item;
while (((in + 1) % BUFFER_SIZE == out); /* do nothing -- no free buffers */
buffer[in] = item;
in = (in + 1) % BUFFER_SIZE;
}
Consumer 代码如下:
while (true) {
while (in == out); //do nothing, nothing to consume
// Remove an item from the buffer;
item = buffer[out];
out = (out + 1) % BUFFER SIZE;
return item;
}
有一个小小的麻烦:Solution is correct, but can only use BUFFER_SIZE -1 elements。
- 考虑 buffer = 2,只有先加两个 item,后取出两个,此时 in 和 out 的值都是存在的。之后,加一个,in 变成 0 了,再加一个,则in = out,也就是说,少用了一个 buffet。
如果想使用 BUFFER_SIZE 大小的共享内存的话,我们可以这样做:
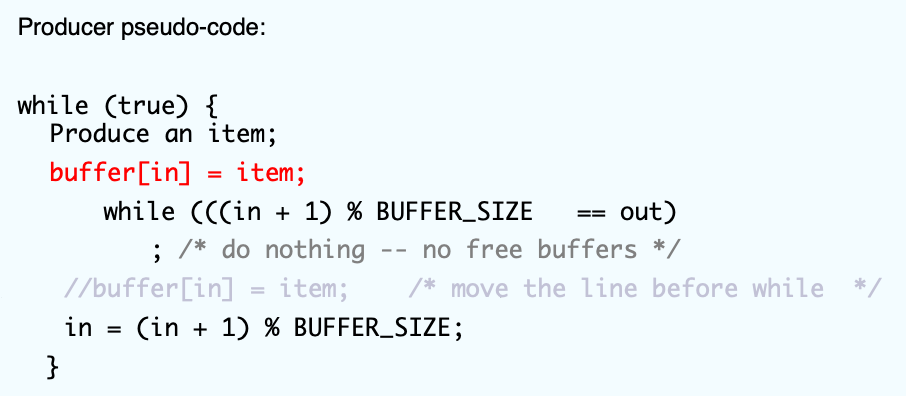
但是,使用这样的方法,也会产生一个问题:当 in == out 的时候,一般情况下,此时队列里面是空的,但是按照这个方法,队列里面 in(out) 的位置上有元素,但我们无法取出。
一种简单的解决方式是使用一个计数器 count:
// producer
while (true) {
Produce an item;
buffer[in] = item;
while (((in + 1) % BUFFER_SIZE == out)
; /* do nothing -- no free buffers */
//buffer[in] = item; /* move the line before while */
count++;
in = (in + 1) % BUFFER_SIZE;
}
// consumer
while (true) {
while (in == out)
; //do nothing, nothing to consume
Remove an item from the buffer;
item = buffer[out];
count--;
out = (out + 1) % BUFFER SIZE;
return item;
} 有了 counter 这个东西,我们就有办法区分“根本没有元素”以及“有元素但 in == out”的情况了,也就是观察 counter 是否为 0。

Written by
ZZC
每天研究怎么摸鱼的神人
Comments
评论功能即将上线