强化学习
Lec1: Basic Concepts in Reinforcement Learning
以方格世界为例,构建强化学习的基础数学框架:状态、动作、奖励、状态转移、策略、轨迹与回报,以及引入折扣率后的折扣回报,最终统一为马尔可夫决策过程(MDP)。
摘要:本讲义以方格世界(Grid-world)为例,系统构建了强化学习的基础数学框架。首先定义了智能体与环境交互的核心要素,包括描述环境状况的状态(State)空间、依赖于当前状态的动作(Action)空间,以及作为人机接口用于引导行为的标量奖励(Reward)。在此基础上,讲义阐述了概率性的状态转移(State transition)机制和智能体选择动作的策略(Policy),并引入轨迹(Trajectory)与回报(Return)来评估策略优劣。为了解决无限视界下的发散问题,进一步提出了引入折扣率 的折扣回报(Discount return)概念。最终,这些要素被统一形式化为马尔可夫决策过程(MDP),其核心特征在于具备无记忆性(Memoryless)的马尔可夫性质,即未来的演变仅取决于当前的状态与动作。
Grid-world example
假设我们有一个机器人在方格中行走,要从 start 到 target。如下图所示:
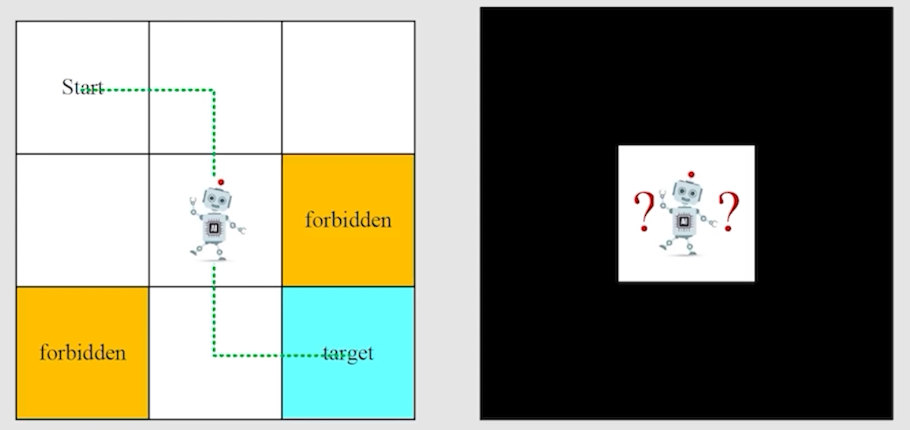
其中,方块有三种类型:Accessible/forbidden/target,同时还有一个边界 boundary。
我们的目标是:
- 从 start 出发,找到一条 good 的路径去达到目标。
- 怎么样定义路径是不是 good 的
State
我们对 State 做如下定义:
- The state of the agent with respect to the enviroment
- 重点在 enviroment上
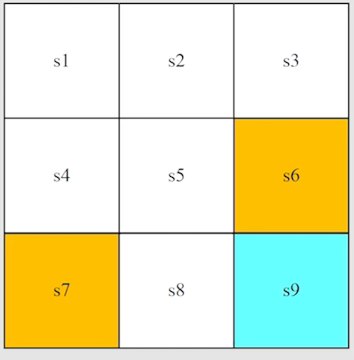
在之前的 grid-world 的例子中,每个位置对应一个状态,实际上都是 state
对于众多的 states,我们可以采用集合的方式来进行表示,更加严谨学术的表达是 state space:
Action
在每一种 state 情况下,智能体都可以进行一系列可能的操作,也就是 actions。
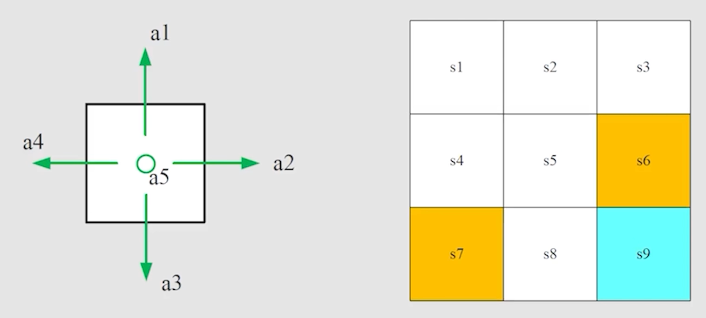
在之前的 grid-world 的例子中,我们可以有 5 种可能的状态:。
和 state 一样,action 可以定义一个空间 action space:
Note
需要注意的是,action space 和 state 是依赖的。也就是说以下论断是成立的:
Differnt states can have different set of actions.
State transition
这个概念和我们在《计算理论》中学习到的 DFA 有点像。都是一个状态要向另外一个状态进行转移,转移过程中需要“吃掉”一个 action。
- Case 1:从 到 :
- Case 2:在 状态下向上走:
- 因为 向上走已经是边界了,因此我们定义 回到原来的位置。
- 实际上,回到哪里都是有可能的,需要根据实际情况去定义
With Forbidden Area
对于 Forbidden area,我们有两种处理方法:
- Forbidden area 是 accessible 的,但是会有 penalty(惩罚):
- Forbidden area 是 inaccessible 的。例如,我们将 Forbidden area 处理为 boundary:
第一种方案更为一般,也更具有挑战性。例如,我们有可能找出一条通过 Forbidden area 的路线,其是最优的。
在之后的内容中,我们讨论的都会是第一种方案。
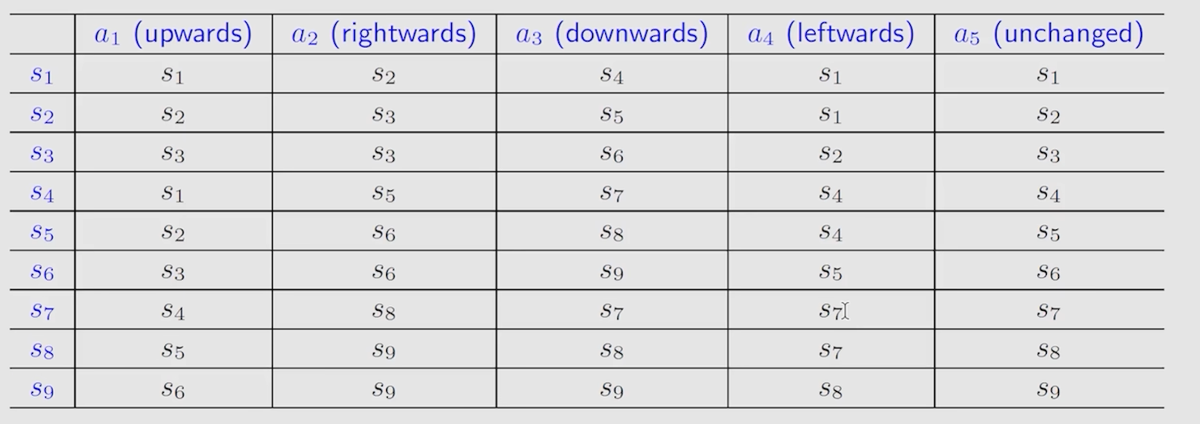
Tabular representation
可以使用表格的方法表示 state transition,但是缺点也很明显:只能表示确定的 state。
State transition probability
更一般的表示方法是使用概率。
例如,假设处于 ,若是我们采取行动 ,下一个 state 是 。这种行为用数学描述如下:
这种表示方式可以描述 storchastic(不确定的) 例子。
Policy
在每种状态下采取某种行为称为策略(policy)。Policy 也可以使用数学概率来表示,比如下面的例子:
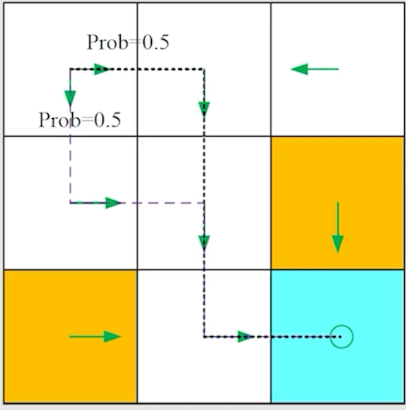
在这个策略中,对于 来说就是:
Tabular representation
Policy 也可以使用表格来描述:
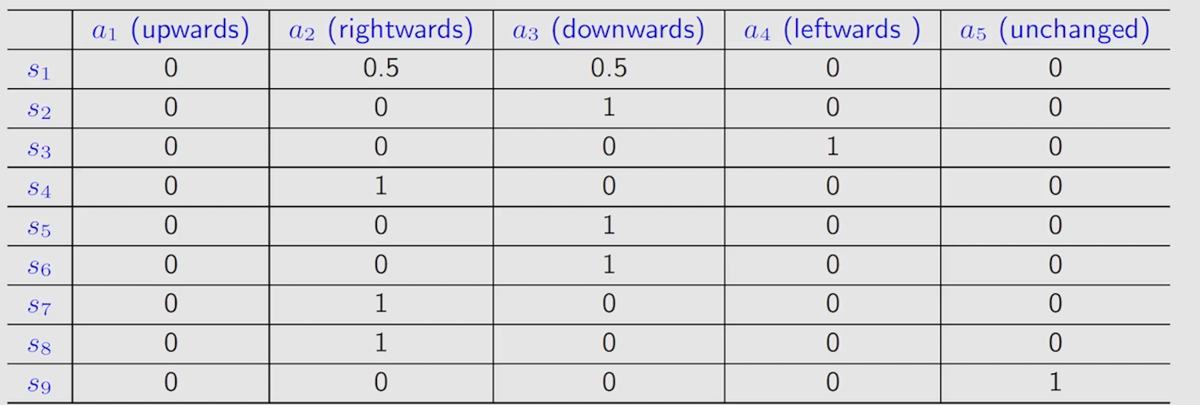
与上面的不同,这里表格既可以表示确定的情况也可以表示非确定的情况。
Reward
Reward 是 RL 中最重要的一个概念。
Reward 是一个我们采取 action 之后获得的标量。
一般来说,positive reward 代表 reward,negative reward 代表 punishment。
Note
可以存在数值为 0 的 Reward 吗?
可以,这意味着没有 punishment。
Note
可以让 positive reward 作为 punishment 吗?
可以,实际上,这是一种较好的数学技巧。
Example
以之前的 Grid-world example 为例子,定义奖励如下:
- 若 agent 想要走出边界,则
- 若 agent 想要进入一个 forbidden cell,则
- 若 agent 进入了 target cell,则
- 否则,
以上的设计是想要鼓励 agent 不要进入 forbidden area,不要碰到边界,要到达 target area。
Human-machine interface
我们可以将 Reward 看成人类和 agent 交互的一个接口。通过 Reward,我们让 agent 做出我们想要它做的事情。
Tabular representation
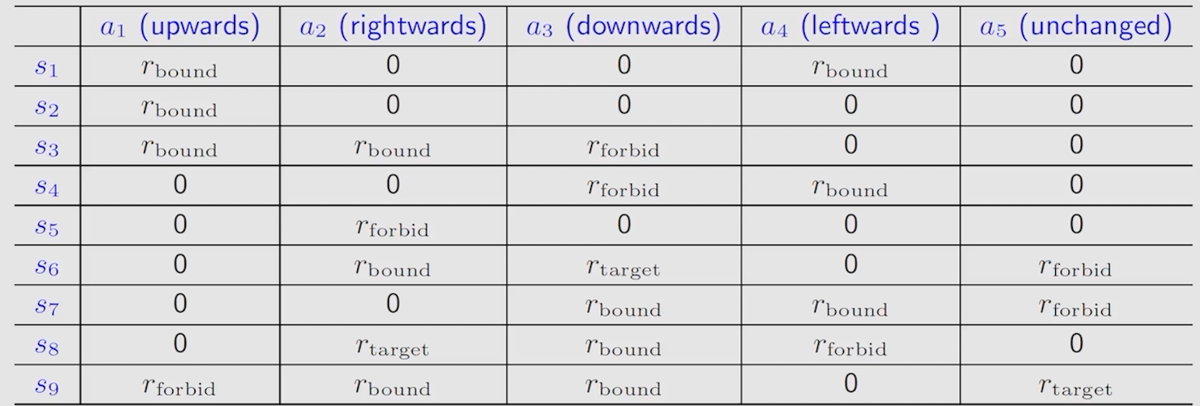
和之前一样,我们也可以使用表格的方法来表示 reward。然而,这里的表格只能表示确定的情况。
Mathematical description
采用更一般的表示方法:
以上结果可能是不确定的。
Trajectory & Return
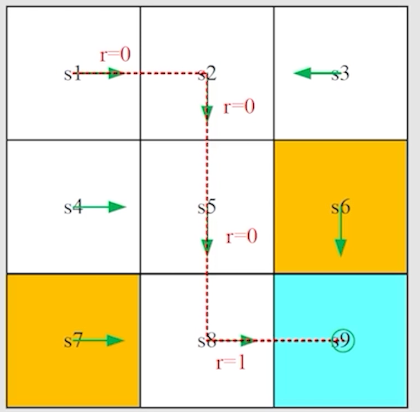
Trajectory 就是一个 state-action-reward chain。例如,对于以上例子,trajectory 如下:
对于一个 Trajectory,我们称这条链上 Reward 的总和为 return。例如:
另外一个例子如下:
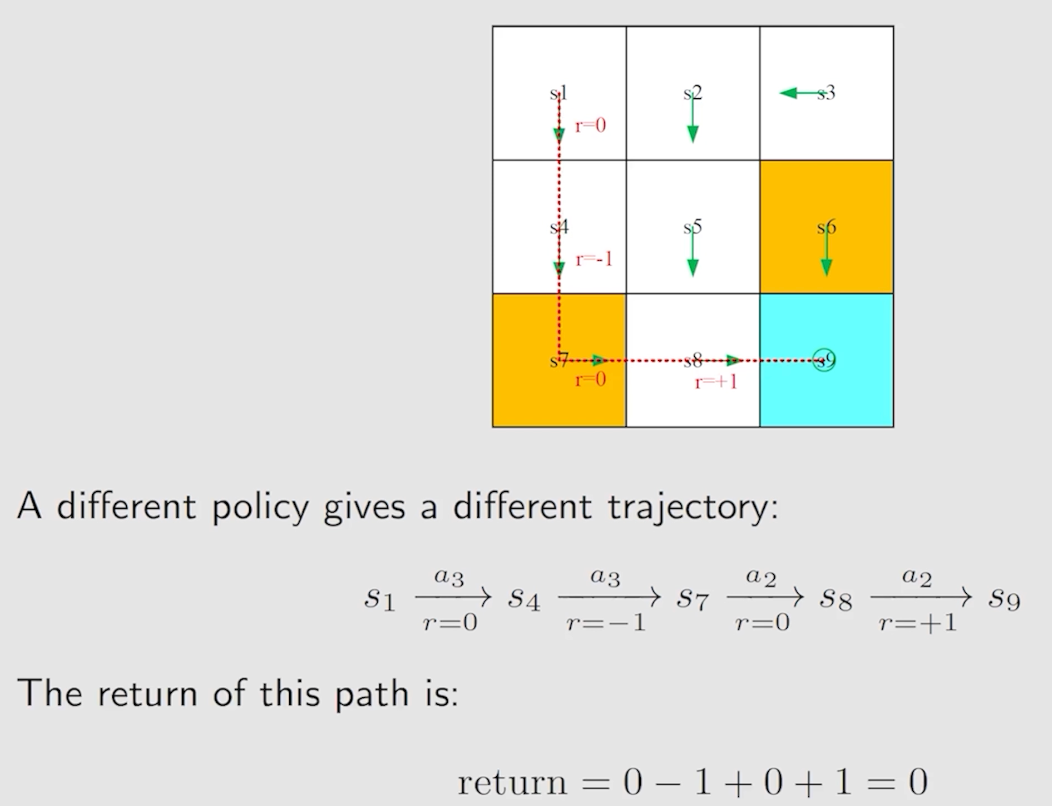
- 实际上,我们可以使用 Trajectory 和 Return 取评估一个 policy 是好是坏
Discount return
然而,上面所说的情况可能会出现一些问题:最后有可能会在 target cell 无限累加:
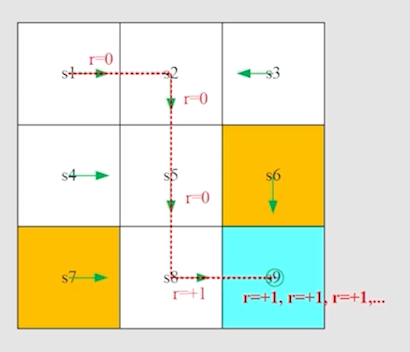
也就是:
很显然这并不是我们希望看到的结果,因为这是发散的。
因此,我们采取了一种类似于“公比小于 1 的等比数列累加和小于一个常数”的想法,引出 Discount rate:
我们称 为 discount rate。
对于 discount return,我们可以确定其一定是收敛的。
关于 ,我们还可以利用其控制 agent 对远近未来 Reward 的关注程度:
- 若 更偏向于 0,那么 return 受开始 reward 影响更大。(近视)
- 若 更偏向于 1,那么 return 受未来 reward 影响更大。(远视)
Episode
对于 agent,若其最终可以停止在某些 terminal states,那我们就称 resulting trajectory 为 episode。
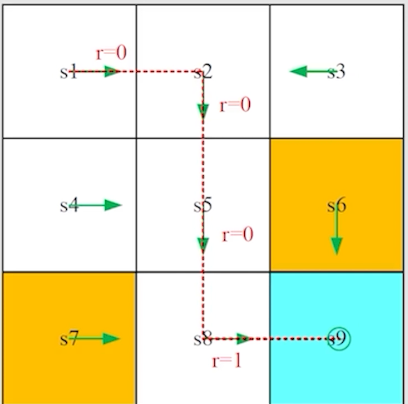
在上面的例子中,episode为:
对一个有 episodes 的 tasks 来说,我们称之为 episodic task。
Continuing tasks
有些任务可能并没有 terminal state 的,意味着 agent 和外界的交互可能永远都不会停止。这样的任务我们称为 continuing tasks。
事实上,在一般情况下,我们都是将 episodic tasks 处理成 continuing tasks 的,这样更符合一般性。我们有两种方案:
- 将 target state 视作一种特殊的 absorbing state。一旦 agent 到达一个 aborbing state,其就永远不会结束,接下来连续的 reward
- 将 target state 视作带 policy 的 normal state。agent 可以离开 target state 并且再一次得到 当其重新进入 target state。
我们选择方案二,因为这种方案让我们不需要去区分 target state 和别的 normal state。
Markov decision process(MDP)
Key elements of MDP
- Sets:
- State:
- Action:
- Reward:
- Probability distribution:
- State transition probability:
- Reward probability:
- Policy:
Markov Property
-
Memoryless:
Markov process
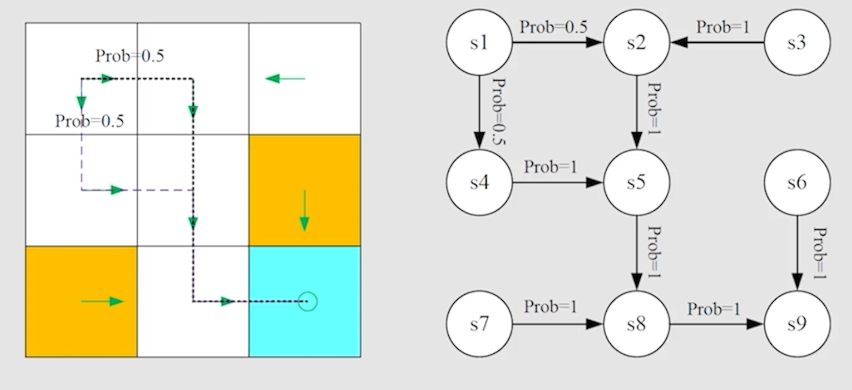
我们可以使用上面的图来表示 Markov process。
当 policy is given,Markov process become Markov decision process。

Written by
ZZC
每天研究怎么摸鱼的神人
Comments
评论功能即将上线